目次 - Lesson3
ネットワークとインターネットの仕組み
Lesson 3Chapter 1学習の目標
このレッスンでは、ネットワークとインターネットの仕組みについて学びます。
日常生活で当たり前のように使われているスマートフォンやパソコン、その裏側で動いているWi-Fi、クラウドサービスなどは、すべて「ネットワーク」が支えています。
ネットワークは、通信機器やケーブル、無線技術を組み合わせて構成されます。私たちがインターネット経由で情報をやり取りできるのは、これらの仕組みが相互につながり、データを最適なルートで届けているからです。
本レッスンでは、ネットワークの構成やインターネットを支える技術的要素について、段階的に理解を深めます。ネットワークがどのようにデータをやり取りし、世界中の情報を結びつけているのか、その全体像をつかむことを目指しましょう。
本レッスンの主な内容
- ネットワークとは
- ネットワークの構成
- インターネットとは
- URL
- IPとDNS
- HTTP(HTTPS)
- TCP/IPモデル
- インターネットを活用したサービス
本レッスンのゴール
ネットワークとインターネットの基本的な仕組み、関連技術、およびそれらがどのようにつながり合っているかを正しく理解すること
本レッスンの前提条件
- ビジネスパーソンに必要なITスキルを把握していること(レッスン1)
- コンピュータの中身について正しいイメージを持っていること(レッスン2)
Lesson 3Chapter 2ネットワークとは
ネットワーク とは、複数の機器を互いに接続してデータを送受信できるようにした仕組みです。
たとえば家庭内のWi-Fiを使うと、スマートフォンからインターネットに接続できます。このときスマートフォンは、Wi-Fiルーターを経由して、「インターネット」という巨大なネットワークとつながっています。
この「つながり=ネットワーク」があるからこそ、Webサイトを閲覧したり、動画を視聴したりといった、多種多様な活動が可能になるのです。
Lesson 3Chapter 2.1身近なネットワークの例
私たちは日常生活のなかで、無意識のうちにネットワークを利用しています。いくつか例で確認しましょう。
スマートフォンとWi-Fi
自宅のWi-Fiルーターにスマートフォンを接続し、インターネットでニュースサイトを閲覧したり、YouTubeで動画を見たりすることができます。
このとき、スマートフォンとWi-Fiルーターが無線でつながっており、ルーターがさらにインターネットサービスプロバイダ(ISP)の回線を通じて世界中のサーバーと接続しています。
パソコンとプリンター
パソコンとプリンターをUSBケーブルで直結する代わりに、プリンターを自宅のWi-Fiネットワーク(LAN)につないでおけば、同じネットワーク内にあるパソコンから無線で印刷できます。これにより、部屋が異なっていても印刷が可能です。
クラウドサービス
スマートフォンで撮影した写真をクラウドサービス(例えばGoogle DriveやiCloud)にアップロードすると、ネットワークを通じて遠く離れたサーバーに保存され、あとでパソコンやタブレットからも参照できます。
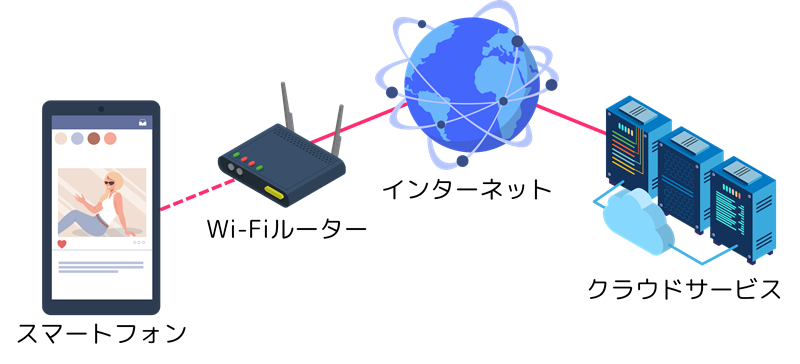
ネットワークのイメージ図
Lesson 3Chapter 2.2ネットワークが送受信するのはデジタルデータ
ネットワークは、目に見えるケーブルやアンテナだけでなく、目には見えない電気信号や電波を用いて情報を届けています。ネットワークを通して送られる情報は、文字情報だけでなく、画像や動画、音声、アプリの操作データなどさまざまです。これらはデジタルデータ(0と1の組み合わせ)として扱われ、情報の送り手から受け手へと伝わります。
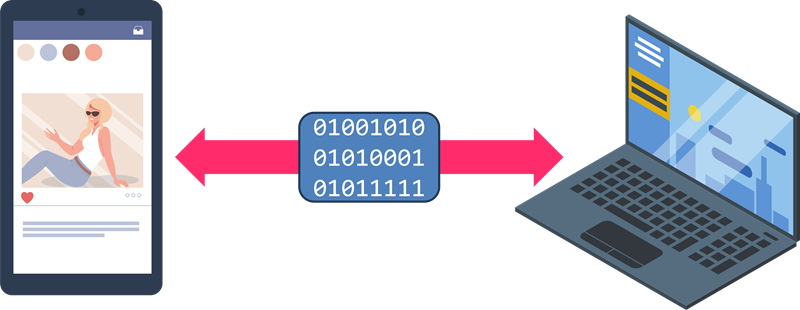
情報の送り手から受け手へと伝わるデジタルデータ
Lesson 3Chapter 2.3LANとWAN
ネットワークは大きさや範囲によって、LANとWANに分けられます。
LANは身近な小さなネットワークで、WANは広大な範囲にネットワークを広げた概念です。
LAN(ラン:Local Area Network)
LAN は、家やオフィス、学校など比較的狭い範囲で構成されるネットワークを指します。たとえば自宅で、Wi-Fiルーターを中心としてパソコンやスマートフォン、プリンターがつながっている範囲は「家庭内LAN」と言えます。
WAN(ワン:Wide Area Network)
WAN は、より広範囲にわたるネットワークを指します。代表的なWANが「インターネット」です。
インターネット は、世界中の無数のLANが互いにつながった巨大なWAN(ネットワークのネットワーク)です。
自宅や会社、学校のLANがインターネットにつながると、世界中のサーバーやサービスへアクセスできるようになります。
WANを構築するためには、遠く離れた拠点同士をつなぐ長距離通信回線が必要になります。これらは通常、「電気通信事業者」が提供する専用回線やインターネット接続サービスなどを利用します。組織が自前で数百km先の拠点までケーブルを引くことは現実的でないためです。
電気通信事業者
電気通信事業者 は、電話、インターネット、専用回線など、通信サービスを一般ユーザーや企業に提供する事業者(企業)のことです。
具体的には、固定電話や携帯電話、光ファイバー回線、ブロードバンドインターネット接続などを提供する企業です。日本で言えば、NTT、KDDI、ソフトバンクといった企業がこれに該当します。
これらの事業者が整備したインフラや回線を利用することで、組織や家庭は自ら遠距離用の物理回線を敷設することなく、遠隔地と通信できるようになります。
ネットワークやインターネットは、私たちの日常を非常に便利にしています。たとえば、オンラインショッピング、遠隔会議(ビデオチャット)、メール、SNS、オンラインゲームなど、挙げればきりがありません。これらはすべて、ネットワークという「道」を通じて、データ(情報)が機器と機器、サービスとユーザーの間を自由に行き来しているからこそ実現しているのです。
Lesson 3Chapter 3ネットワークの構成
ネットワークは以下で構成されます。
- デバイス:
パソコンやスマートフォンなど、ネットワークに接続される個々の機器。 - ネットワークを支えるハードウェア機器:
ネットワークを構築・運用するための機器。 - 通信媒体
LANケーブルやWi-Fiなど、データを送受信するための物理的、または無線の経路。
順番に確認していきましょう。
Lesson 3Chapter 3.1デバイス
デバイス は、パソコンやスマートフォンなど、ネットワークに接続される個々の機器です。
デバイスには、サービスを利用する側の「クライアント」と、サービスを提供する側の「サーバー」があります。
サーバーとクライアントの関係
クライアント
クライアント(Client)は、サービスを利用する側のデバイスです。パソコンやスマートフォン、タブレットなどは、Webサイト閲覧やメール送受信などを行なうクライアントとして動作します。
- パソコンやスマートフォン:日常的に使う代表的な端末です。Web閲覧やメール、動画視聴など、さまざまなサービスを利用できます。
- ゲーム機やスマート家電:ネットワークにつながることで、オンラインで対戦ゲームをしたり、遠隔でエアコンのスイッチを入れたりできます。
サーバー
サーバー(Server)は、サービスを提供する側のデバイスです。たとえば、あなたがWebサイトにアクセスしたとき、ページの情報を提供してくれるのは「Webサーバー」です。
- Webサーバー:Webページのデータを提供します。
- メールサーバー:メール本文や添付ファイルを送受信します。
- クラウドストレージサーバー:各種ファイルを格納・提供します。
クライアント・サーバーモデル
クライアントとサーバーがやり取りすることで、私たちはネットワークを通じて必要な情報を取得しています。このような役割分担の通信方式を クライアント・サーバーモデル と呼びます。
クライアントとサーバーは、同じネットワーク上に存在する場合もあれば、インターネットなど外部のネットワークを介して接続される場合もあります。オフィス内の共有フォルダはLAN上のサーバーであり、社内のパソコン(クライアント)から直接アクセスできます。一方、クラウドサービスのように遠隔地のデータセンターにあるサーバーへは、インターネットを通してアクセスします。このような端末同士の役割分担と連携が、ネットワークの利便性と柔軟性を支えています。
参考:ソフトウェアとしてのクライアントとサーバー
クライアントとサーバーは、物理的なデバイスだけでなく、ソフトウェアを指す用途にも使われます。
- クライアントソフトウェアの例:
- ブラウザ、メールクライアント、ファイル転送クライアント、チャットアプリなど
- これらはユーザーが操作するアプリケーションで、物理機器上で動作し、サーバーに対してリクエストを送るためのソフトウェアです。
- サーバーソフトウェアの例:
- Webサーバーソフト(Apache、Nginx)、メールサーバーソフト(Postfix、Exchange)、ファイルサーバーソフト(Samba)、データベースサーバーソフト(MySQL、PostgreSQL)など
- これらはサーバー用コンピュータ上で稼働し、クライアントからの要求に応じて適切な情報を返すソフトウェアです。
Lesson 3Chapter 3.2ネットワークを支えるハードウェア機器
ネットワークを支える裏方には、多くのハードウェア機器が存在します。これらは、データの振り分けや変換、増幅を通じて、効率的な通信を実現します。
ルーター
ルーター は、異なるネットワーク間をつなぐ機器です。データをどの経路で送るか判断する役割を持ちます。
たとえば自宅のWi-Fiルーターは、LAN(家庭内)とWAN(インターネット)を接続し、外部へアクセスする際の出入り口となります。

ルーターの例: TP-Link ER605
ハブ
ハブ は、同じLAN内で、複数のデバイスを単純に接続する装置です。
ハブは、データの宛先を判断せず、一斉に放送(ブロードキャスト)するため、ネットワークトラフィックが増え、非効率的になることが多いです。
ハブは安価で構造がシンプルですが、現在ではより高性能な「スイッチ」が主流になっています。
スイッチ
スイッチ は、同じLAN内で、接続された複数の端末に対してデータを振り分ける機器です。
スイッチは、どの端末宛てのデータなのかを「MACアドレス(後述)」という情報を用いて判断するため、ハブよりも効率的にデータを届けることが可能です。

スイッチの例: Cisco Catalyst 2960 シリーズ
モデム
モデム は、通信事業者の回線(電話線やケーブル回線、光回線など)を、パソコンやルーターで扱える信号形式に変換する装置です。
たとえば、光回線終端装置(ONU)は、光信号を家庭で扱えるイーサネット信号に変換するモデムです。モデムは、電気信号・光信号・アナログ/デジタル変換など、異なる物理層を橋渡しします。
モデムの例: NTT東日本
NIC(ネットワークインターフェースカード)
NIC は、コンピュータがネットワークに接続するための拡張カードやチップです。LANポートやWi-Fiアダプタなどが該当し、端末とネットワークを物理的・論理的につなぎます。現在ではほとんどのパソコンやスマートフォンに標準搭載されています。
Lesson 3Chapter 3.3通信媒体
通信媒体 は、データを送受信する際に使用される物理的または電磁的な経路のことです。LANの通信媒体には、主に有線LANと無線LANの2種類があります。
| 項目 | 有線LAN | 無線LAN |
|---|---|---|
| 通信速度と安定性 | 高速で安定 | 比較的遅く、不安定な場合も |
| 設置コスト | ケーブル配線が必要で高い | 配線不要で低コスト |
| 移動性 | 固定的 | 高い自由度 |
| セキュリティ | 高い(物理的アクセスが必要) | 暗号化などで対策が必要 |
| 主な接続方式 | イーサネットケーブル、光ファイバー | Wi-Fi |
有線LAN
有線LAN は、ケーブルを使用してネットワーク機器を接続する通信方式です。
- メリット:
- ケーブルを用いることで、高速かつ安定した通信が可能です。
- 電磁波や障害物の影響を受けにくいため、速度が理論値に近づきやすいです。
- デメリット:
- ケーブル配線が必要で、設置時に手間がかかり、移動の自由度が制限されます。
- 主な用途:
- オフィスやデータセンター、家庭での固定回線接続に利用されています。
接続にはイーサネットケーブルや光ファイバーなどが使用されます。
- イーサネットケーブル:
一般的なLAN構築に用いる銅線ケーブルです。カテゴリー5e、6、6Aなど、性能ごとに規格がわかれ、最大通信速度と伝送距離に影響します。 - 光ファイバー:
ガラス繊維を用いて光信号でデータを送るケーブルです。遠距離でも高速・大容量通信が可能ですが、導入コストや施工が有線LANよりも高くなります。インターネット接続で家庭用光回線として利用されるほか、企業や電気通信事業者間のバックボーン回線で使われます。

イーサネットケーブル(LANケーブル)の例: エレコム Cat8準拠LANケーブル
無線LAN
無線LANは、電波を用いてデータを送受信する通信方式です。
- メリット:
- ケーブルを必要としないため、設置が容易で、デバイスの移動や接続が柔軟に行なえます。
- デメリット:
- 電磁干渉や障害物(壁や家具など)によって通信速度や安定性が影響を受けることがあります。
- 電波を傍受されないよう、セキュリティ対策(暗号化や認証)が必要です。
- 主な用途:
- スマートフォン、タブレット、ノートパソコンなどのモバイルデバイスを中心に、家庭や公共の場で広く利用されています。
接続には、Wi-Fiなどの規格があります。
- Wi-Fi規格:
IEEE 802.11シリーズとして定められ、802.11n、802.11ac、802.11ax(Wi-Fi 6)など、新しい規格になるほど高速かつ高品質な通信をサポートします。周波数帯は2.4GHz帯と5GHz帯が一般的で、障害物への強さや最大速度に違いがあります。

Wi-Fiルーターの例: BUFFALO WSR-3000AX4Pシリーズ
参考:伝送効率と伝送時間
通信媒体には、「理論上はこれくらい速く送れる」という限界(回線速度)がありますが、実際にデータを送るときの本当の速さ(伝送速度)は、いろいろな要因で落ちてしまうことがよくあります。
伝送効率 とは、実際にデータをやり取りする速さ(伝送速度)が、その回線が理論的に出せる最大スピード(回線速度)に対して、どのくらいの割合になっているかを表すものです。
計算式:
伝送効率 = 伝送速度 ÷ 回線速度
たとえば、インターネット回線が理論上「100Mbps」で出せるはずなのに、実際には「50Mbps」しか出ていなければ、伝送効率は 50Mbps ÷ 100Mbps = 0.5(50%) となります。つまり、用意された回線の半分くらいのスピードしか出せていない、ということです。
伝送時間 とは、送りたいデータの量を、実際の伝送速度で送るのにどれくらい時間がかかるかを示すものです。
計算式:
伝送時間 = データ量 ÷ 伝送速度
たとえば、1GB(約1000MB)のデータを、伝送速度 100MB/秒 の回線で送ると10秒かかります。
伝送時間 = 1000MB ÷ 100MB/秒 = 10秒
以下は、イーサネットとWi-Fiの、代表的な規格と速度の例です。
イーサネットの代表的な規格
イーサネットの伝送速度は、ネットワークの構成や使用する機器、ケーブルの品質、その他の環境要因によって変動します。
| 規格名 | 回線速度 | 伝送速度の目安 |
|---|---|---|
| 100BASE-TX(ファストイーサネット) | 100 Mbps | 約80~90 Mbps |
| 1000BASE-T(ギガビットイーサネット) | 1 Gbps (1000 Mbps) | 約800~900 Mbps |
| 10GBASE-T(10ギガビットイーサネット) | 10 Gbps (10000 Mbps) | 約8~9 Gbps |
Wi-Fiの代表的な規格
Wi-Fiの伝送速度は、電波の干渉、距離、障害物、接続するデバイスの性能など、多くの要因によって影響を受けます。
| 規格名 | 回線速度 | 伝送速度の目安 |
|---|---|---|
| IEEE 802.11g(Wi-Fi 3) | 54 Mbps | 約20~25 Mbps |
| IEEE 802.11n(Wi-Fi 4) | 600 Mbps | 約100~150 Mbps |
| IEEE 802.11ac(Wi-Fi 5) | 6.9 Gbps | 約600~800 Mbps |
| IEEE 802.11ax(Wi-Fi 6) | 9.6 Gbps | 約800 Mbps~1.2 Gbps |
Lesson 3Chapter 4インターネットとは
インターネット は、地球規模でコンピュータやネットワーク同士がつながった、巨大なネットワークの集合体です。
もともとは限られた研究機関や大学で情報を共有するために生まれたシステムでしたが、現在では家庭や企業、各種サービスに至るまで、ほぼあらゆる場所で利用されるようになり、私たちの日常にはなくてはならない存在となっています。

Lesson 3Chapter 4.1インターネットの歴史
インターネットは1960年代末に、米国国防総省の研究機関ARPA(現在のDARPA)が中心となって開発した「ARPANET」というネットワークから始まりました。当初は研究機関や大学間での情報共有が目的でしたが、1980~90年代に大学や企業、一般家庭へと利用が広がり、World Wide Web(WWW)の普及とともに急速に一般化しました。
その後、1990年代後半から2000年代にかけてブロードバンド回線(高速インターネット接続)や無線LANが普及し、2000年代後半からスマートフォンの登場によって、インターネットは携帯端末を通じて常に身近な存在となりました。
Lesson 3Chapter 4.2インターネットの特徴
インターネットには、以下のような特徴があります。
分散性と冗長性
インターネットは特定の「親分」的な中心があるわけではありません。世界中のネットワークが自律的に相互接続しているため、一部の地域が障害を起こしても、ほかの経路を通って通信できる柔軟性があります。
グローバルアクセス
インターネットに接続していれば、地理的な制約にとらわれず、世界中の情報やサービスにアクセスできます。これによって、地域格差を超えた情報共有が可能になっています。
多様性と拡張性
誰もが新しいサービスを立ち上げたり、新しいコンテンツを発信したりできます。オープンな設計とプロトコルによって、新技術や新規事業が生まれやすくなっています。
Lesson 3Chapter 4.3インターネットを支える技術
インターネットは、以下の技術に支えられています。
- URL:インターネット上の住所
- IPアドレス:ネットワーク上で個々のコンピュータを特定するための番号
- DNS:URLをIPアドレスに変換する仕組み
- HTTP(HTTPS):インターネットでデータをやりとりする通信手段
- TCP/IPモデル:インターネットで主に使われる通信プロトコル(通信の規約)
このレッスンで順番に確認していきましょう。
Lesson 3Chapter 5URL
インターネットを理解するには、URLの理解が不可欠です。これから、インターネットで接続先を特定できるしくみについて学んでいきます。「指定したURLへアクセスするとWebページが表示される」ということについて深掘りしていきましょう。
Lesson 3Chapter 5.1URLはインターネット上のリソースの住所
https://www.google.co.jp/ や http://news.yahoo.co.jp/pickup/1 のような URL は「Uniform Resource Locator」の略称で、日本語に訳すと「統一資源位置指定子」となります。
URLはインターネット上のリソース(資源)の位置を特定するために使用される文字列です。URLはインターネット上に公開されている各リソースに対してユニークに割り当てられ、言い換えれば リソースをインターネット上で特定するための住所 のようなものです。
URLとURIの違いについて
URLに似た用語としてURI(Uniform Resource Identifier、統一資源識別子)があります。厳密にはURIとURLには違いがありますが、日常用途では「大きな違いはない(同じである)」とみなしても問題はありません。
Lesson 3Chapter 5.2URLスキームの一般形式
HTTP通信のURLは http:// で始まる文字列です。この http の部分を URLスキーム と呼びます。
URLスキームの一般形式は以下の通りです。
(プロトコル名、例えばhttp):(プロトコルごとに定められた形式)
URLの最初に付く記号は http 以外にもいくつかあります。参考までに覚えておくと良いでしょう。
- https
- ftp
- mailto
- file
Lesson 3Chapter 5.3HTTPのURLの構成
HTTP以外のURLも確認しましたが、インターネットに接続する限り、一般的な通信プロトコルはHTTPです。ここからはHTTPを基本として解説します。HTTPSの場合も http が https になるだけで同様と考えてください。
具体的なURLの説明へ入る前に、URLを現実世界の住所に例えてみましょう。URLはインターネット上のリソースの位置を特定するための住所のようなものでした。これを現実世界の住所とリソースに例えて考えます。
住所の特定
地球上の1つのリソース(資料など)を特定するなら、どのようにすれば良いでしょうか。話を簡単にするため、範囲を日本国内に限定します。
まずは住所です。東京都渋谷区1-2-5 と書けばリソースが存在する領域をある程度特定できます。
次にビル名を加えると、 東京都渋谷区1-2-5 MFPR渋谷ビル となり、位置がより明確になります。
さらに階数と部屋番号を加えてみます。 東京都渋谷区1-2-5 MFPR渋谷ビル 801号室。ここまで来ると、リソースにかなり近づいてきました。
最後に、完全に特定しましょう。東京都渋谷区1-2-5 MFPR渋谷ビル 801号室 の手前から3番目の机の真下においてある引き出しの 上から3番目にある黄色い表紙の資料。これで日本という広大な空間から、間違う余地なく、1つのリソースを特定できました。
HTTPのURLの一般形式
URLは、上記の発想とまったく同じです。
HTTPのURLの一般形式は下記の通りです。この形でインターネット上のリソースを1つに特定できます。
HTTPのURLの一般形式
http://ホスト名.ドメイン名:ポート番号/パス
HTTPのURLの構成は、いくつかのパーツに分けられています。全体を確認するために下記の表を見てください。
| 用語 | 候補例 | 説明 | 現実世界の例 |
|---|---|---|---|
| ホスト名 | www, mail, maps, news など |
コンピューター | 何階何号室 (901号室など) |
| ドメイン名 | yahoo.co.jp, google.co.jpなど |
ネットワーク名 | ビル名までの住所 (東京都渋谷区1-2-5 MFPR渋谷ビルなど) |
| ポート番号 | 80, 25, 110, 443 など |
通信する番号 | 宛名、宛先の部署名など |
| パス | /magazine/9081, /pg/list.html など |
ホスト内のリソースの場所 | 物の場所 (引き出しの上から3番目の黄色い表紙の資料など) |
これらの用語について説明します。
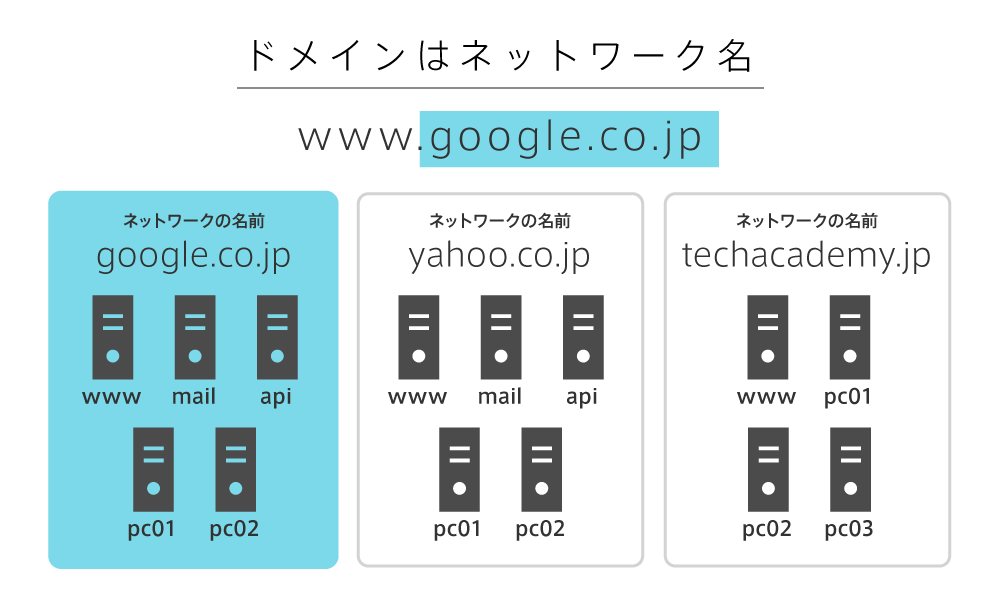
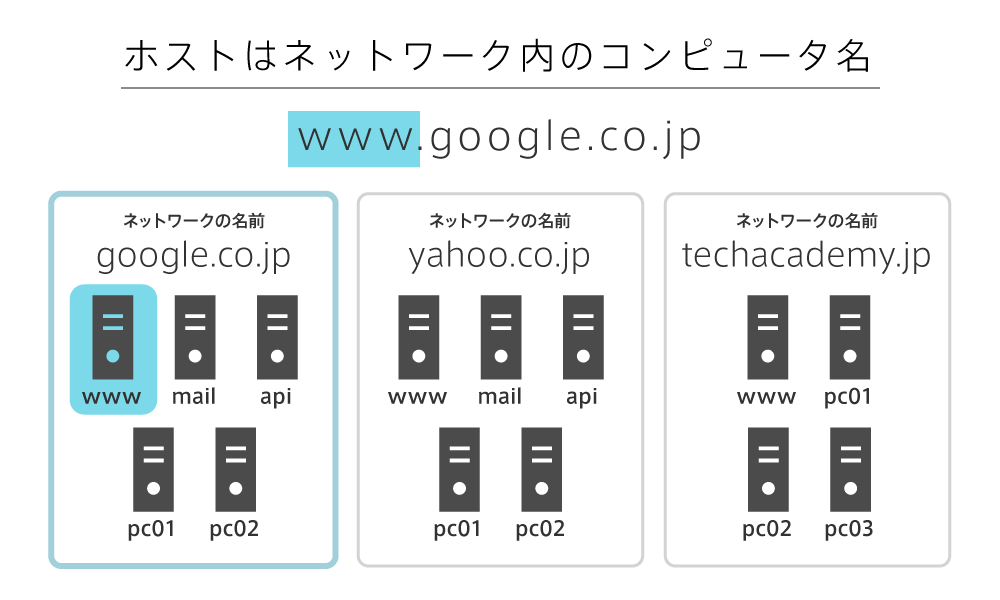
ドメイン名
ドメイン名とは、インターネット上のネットワークを特定するための住所です。たとえば google.co.jp というドメイン名は、日本(co.jp)におけるGoogleのネットワークの住所を表しています。
ホスト名
ホスト名とは、ネットワーク上のコンピューターにつける識別用の名前です。たとえば www.google.co.jp はドメイン名が google.co.jp で、ホスト名が www です。ホスト名の決定は自由ですが、とくに www は、Webサーバーが起動しているホスト名を指すことが多いです。
ポート番号
ポート番号は、通信プロトコルと密接に関連しています。たとえばHTTP通信のURLでは、デフォルトで80番のポート番号を使用するため、80 というポート番号の記述は省略できます。ただし例外的に「HTTPではあるが80番ポートを使わずに3000番を使う」ような場合は 3000 というポート番号を明記することで対応できるようになっています。
ポート番号が必要な理由については、次のチャプターで解説します。
パス
パスとは、コンピューター内のファイルの位置を示したものです。 / によってフォルダ名を区切ります。たとえば /news/tech/computer.html であれば、news フォルダ内の tech フォルダ内にある computer.html ファイルを指定しています。
パスが省略された場合には、index.html などのファイルがデフォルトで表示されます。
URLの一例
たとえば、以下のようなURLがあるとします。
http://www.example.com/news/tech/computer.html
このURLを分類すると以下のようになります。
| 分類 | 該当の部分 |
|---|---|
| 通信プロトコル | http |
| ホスト名 | www |
| ドメイン名 | example.com |
| ポート番号 | 80 が省略されている |
| パス | /news/tech/computer.html |
これらが定まることで、インターネット上のリソースを特定できます。
Lesson 3Chapter 6IPとDNS
インターネット上で特定のサーバーが持つリソースにアクセスするためには、URLが使用されることを学びました。
しかし、実際にはインターネット上のコンピューターの住所を特定するのは IPアドレス であり、URLではありません。URLはIPアドレスに変換される必要があります。
Lesson 3Chapter 6.1IPアドレスはコンピューターの住所
IP(Internet Protocol)とは、インターネット通信に使用されるプロトコルです。インターネットの通信はIPによって成り立っています。
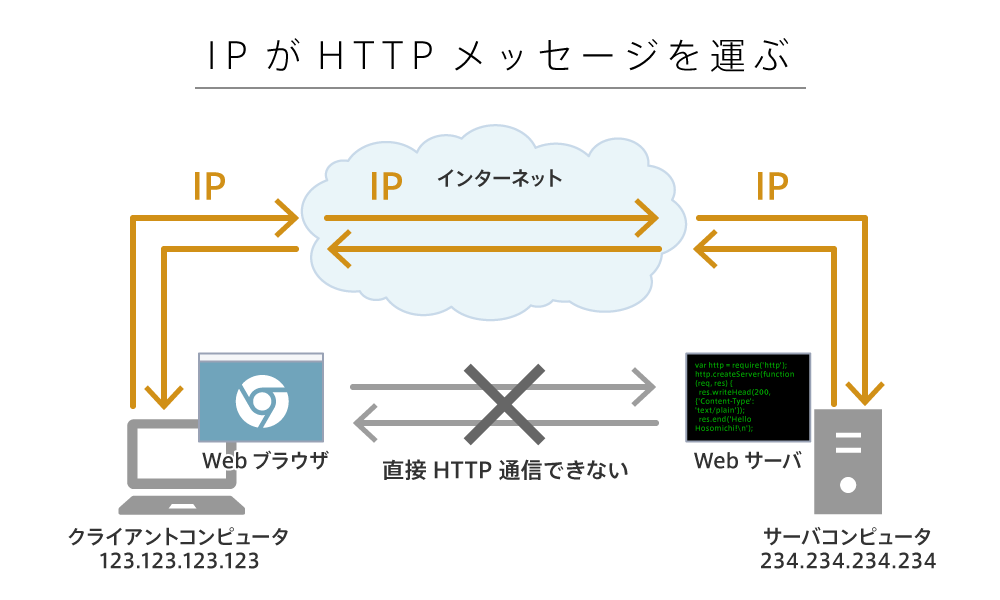
IPがHTTPメッセージを運ぶ
IPがインターネットのプロトコルであるのに対し、HTTPは何でしょうか。HTTPは、インターネットがIPによって接続されているという前提のもと、アプリ同士が通信するためのプロトコルです。つまり、IPこそがインターネットを成立させているプロトコルなのです。
ブラウザがHTTPリクエストメッセージをインターネット上のWebサーバーに送る際、HTTPリクエストメッセージはIPによって運ばれることになります。
IPアドレス
IPアドレスとは、ネットワーク上で個々のコンピューターを特定するための番号(住所)です。ネットワークに接続されている各コンピューターには固有のIPアドレスが割り当てられています。
IPアドレスは、0から255までの数字が . 区切りで、4つ組み合わさった形式で表現されます。たとえば 172.217.161.35 のような値です。この形式では 0.0.0.0 から 255.255.255.255 まで住所を割り当てることができるため、約43億通り(256 x 256 x 256 x 256 = 4,294,967,296)の住所パターンを作り出すことができます。
なお、IPアドレスが重複することはありません。「重複する」ことは「同じアドレス(住所)が複数の場所に存在する」ことになり、どの住所と通信すべきか判断できなくなってしまうためです。
Lesson 3Chapter 6.2URLのホスト名とドメイン名は実はIPアドレス
URLの中の「ホスト名(コンピューター名)とドメイン名(ネットワーク名)の組合せ」がインターネットの住所であると説明してきましたが、実際には「ホスト名とドメイン名の組合せ」は特定のIPアドレスに対応しています。
これは、たとえば www.google.co.jp が 172.217.161.35 に対応している場合、どちらを使用しても同じコンピューターにアクセスできる、ということになります。
www.google.co.jp と 172.217.161.35 を比較すると、人間にとって認識しやすいのは明らかに www.google.co.jp の方です。つまり、「ホスト名とドメイン名の組合せ」は、IPアドレスを人間が理解しやすいように変換したものです。一方、172.217.161.35 のような数値の並びは、コンピューターが内部的に扱うのに適した形式です。
なお、「ホスト名とドメイン名の組合せ」のことを FQDN(Fully Qualified Domain Name、完全修飾ドメイン名) と呼びます。FQDNというキーワードを見かけたら「ホスト名とドメイン名の組合せ」(例 www.google.co.jp)を指していると覚えておきましょう。
Lesson 3Chapter 6.3DNSサーバーがURLとIPアドレスの対応表を持っている
この広大なインターネットの世界で「www.google.co.jp というFQDN(ホスト名とドメイン名の組合せ)のIPアドレスは 172.217.161.35 だと認識する」ためには、何らかのシステムがその対応表を常に持っていて、かつ対応表の管理・保守を続ける必要があります。その役割を担うシステムが DNS(Domain Name System、ドメイン・ネーム・システム) です。DNSが動作しているサーバーのことを DNSサーバー と呼びます。
たとえば、私たちがブラウザのURL入力欄に https://www.google.co.jp/ と入力してアクセスする場合、以下のような流れで www.google.co.jp というFQDNに対するIPアドレスを取得できます。
- ブラウザは、DNSサーバーに「
www.google.co.jpのIPアドレスは何ですか?」と問い合わせる。 - DNSサーバーはその対応表を持っているため、
www.google.co.jpのIPアドレス172.217.161.35をレスポンスとして返す。
この流れを経て、ようやくインターネットを介した通信が可能になります。DNSサーバーにIPアドレスを確認する一連の操作を 名前解決 と呼びます。
DNSサーバーが存在しない場合、https://www.google.co.jp と入力してもIPアドレスを取得できないため、Webページにアクセスできません。この場合は直接 https://172.217.161.35/ のように、IPアドレスをURL欄に入力しなければなりません。人間には覚えきれず非常に不便です。
また、DNSの利点は他にもあります。たとえば、WebサーバーのIPアドレスが変更された場合、個人が対応表を持っていれば自身で更新する必要があります。しかし、DNSサーバーに任せていれば情報の更新はDNSサーバーが自動で行なうため、利用者は www.google.co.jp などのFQDNを覚えてさえいれば、DNSサーバーから容易に新しいIPアドレスを取得できるようになります。
Lesson 3Chapter 6.4DNSサーバーの階層構造とFQDNの名前解決
名前解決をする流れを詳しく見てみます。
www.google.co.jp は . でいくつかの部分に分割されています。それらは www, google, co, jpです。
このなかで、もっとも広い領域を示すのが jp で、これは日本を意味します。次の co は commercial(商用、営利目的)を意味します。その後に続く google は、日本の営利企業であるGoogle社のドメインです。
www はホスト名です。google ドメイン内の www というホストを指しています。
この階層構造は「DNSサーバーの階層構造」と一致しています。名前解決において、この階層構造が重要な役割を果たします。
たとえば www.google.co.jp の名前解決(IPアドレスを取得)の手順は次のようになります。
- 最初に ルートDNSサーバー へ「
jpのDNSサーバーはどこにありますか?」とリクエストを送り、「jpのDNSサーバーのIPアドレス」をレスポンスとして受け取ります。 - それを利用して、次に
jpのDNSサーバーに「co.jpのDNSサーバーはどこですか?」とリクエストを送り、「co.jpのDNSサーバーのIPアドレス」を受け取ります。 - 同様に、
co.jpのDNSサーバーに「google.co.jpはどこですか?」とリクエストを送り、「google.co.jpのDNSサーバーのIPアドレス」を受け取ります。 - 最後に
google.co.jpのDNSサーバーに「www.google.co.jpのホストはどこですか?」とリクエストを送り、該当するIPアドレスを受け取ります。
これで www.google.co.jp のIPアドレスが判明したため、Webサーバーにアクセス(HTTPリクエストを送信)できます。
以下の図で流れを再確認しましょう。
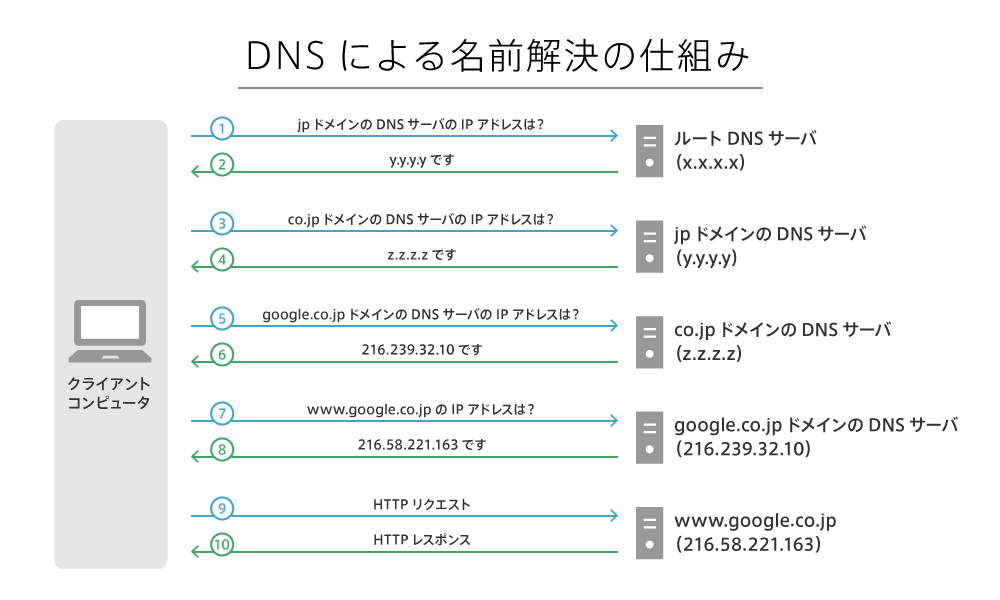
この図は、Webページが表示されるまでの仕組みも示しています。本レッスンの最後には「特定のページへアクセスした際の一連の流れを説明する」課題があります。自身の言葉で説明できるように確認しておきましょう。
参照:DNSキャッシュ(JPNIC)
.jpだけでなく、.com や .net など、DNSサーバーの階層構造はドメインの種類に応じて存在します。これらのドメインも、上記の例のようにルートDNSサーバーから順に名前解決を行ないます。
Lesson 3Chapter 6.5グローバルIPアドレスとプライベートIPアドレス
IPアドレスはネットワーク上で個々のコンピューターを特定するための番号(住所)で、ネットワークに接続している個々のコンピューターは固有のIPアドレスが設定されている、と説明しました。
しかし、厳密には少し異なります。
グローバルIPアドレス
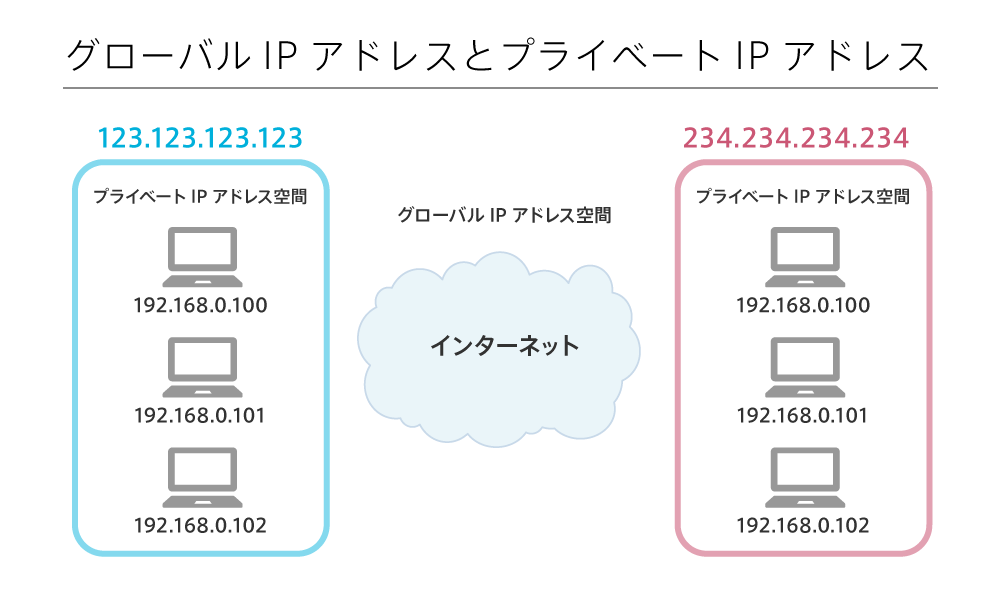
実際にはコンピューターではなく、インターネット上に数多くある「1つの小さなネットワーク」に対して「1つのIPアドレス」が与えられています。そのIPアドレスのことを グローバルIPアドレス と呼びます。
グローバルIPアドレスこそ、インターネット上で唯一のIPアドレスとなります。したがって、172.217.161.35 というIPアドレスが指し示すのは「特定の小さなネットワーク」で、この小さなネットワークはグローバルIPアドレスによって一意に決まります。
プライベートIPアドレス
小さなネットワーク内、つまり家庭や会社などの小さな組織内の、個々のコンピューターに与えられているIPアドレスのことを プライベートIPアドレス と呼びます。プライベートIPアドレスは、192.168.0.100 のように 192.168.xxx.xxx のような値であることが多いです。
プライベートIPアドレスは小さなネットワーク内に限定されたIPアドレスであるため、このアドレスが設定されたコンピューターをインターネット上では特定できません。特定する方法は次のチャプターで説明します。
プライベートなネットワーク内でも「IPアドレスは重複できない」ルールは同じです。1つのプライベートネットワークの中に、IPアドレスが 192.168.0.100 のコンピューターが2台ある状態は許されません。ネットワークエラーになり、通信が正常に行なえなくなります。
逆に言えば、別々のプライベートネットワークであれば、同じIPアドレスを付与できます。以下の図のように、別々のプライベートネットワーク内に、192.168.0.100 という同じIPアドレスが割り当てられている分には問題ありません。
プライベートIPアドレスが生まれた背景
プライベートIPアドレスが生まれた背景には、グローバルIPアドレスの数が一因です。
IPv4の場合、IPアドレスが約43億通りの住所を作れると説明しましたが、早い段階から「将来的にIPアドレスは不足する」と想定されていました。小さなネットワーク内の各コンピューターにまでグローバルIPアドレスを設定すると、すぐに空きがなくなります。
グローバルIPアドレスをネットワークの住所、プライベートIPアドレスをネットワーク内の個々のコンピューターの住所とすることで、グローバルIPアドレスの節約をしているのです。
Lesson 3Chapter 6.6グローバルIPのネットワークからコンピューターを特定するにはポート番号が活躍する
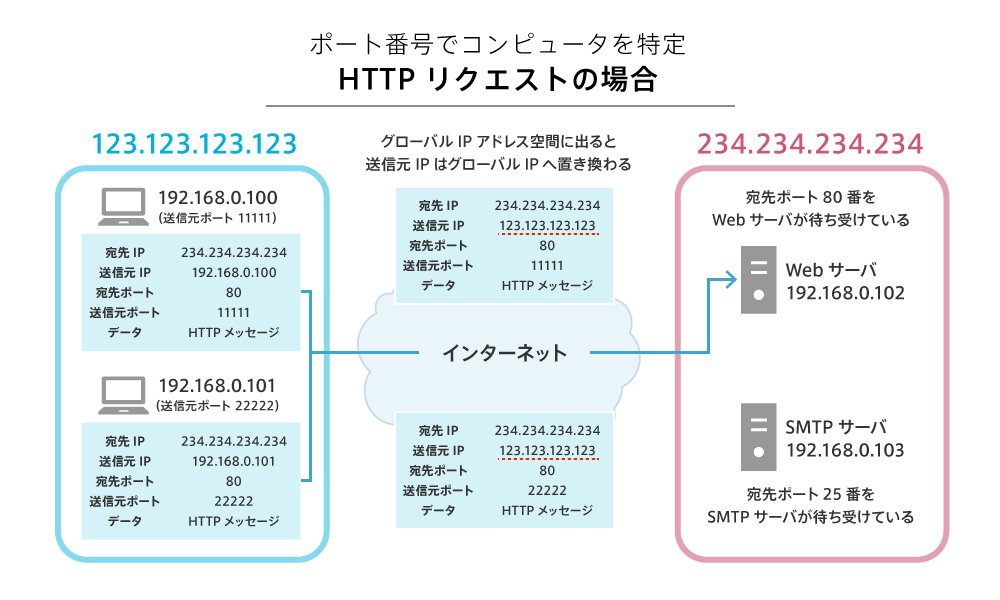
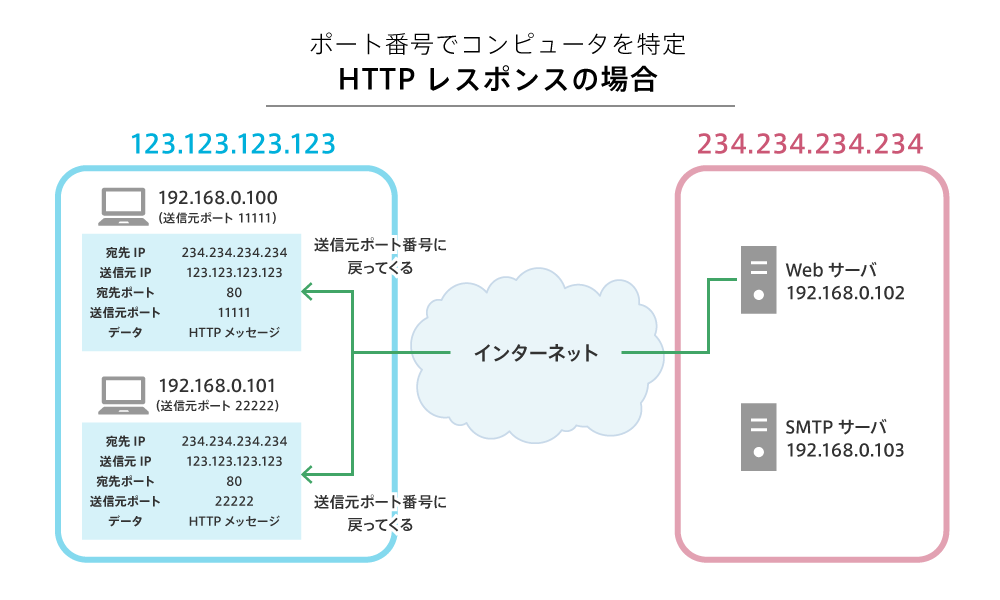
実は、プライベートIPアドレスを使用する際にはある問題が生じます。
プライベートIPアドレスを持つクライアントがサーバーにリクエストを送ると、そのリクエストが「所属するプライベートネットワーク」の外へ出る際に、リクエストに設定された クライアントのIPアドレス(リクエストの送信元) の情報が書き換わってしまいます。
その結果、サーバーが受け取るリクエストに設定されているクライアントのIPアドレスは「所属するネットワークのグローバルIPアドレス」になります。これは、サーバーから見ると「実際にどのコンピューターがリクエストを送ったのか」が特定できないという問題を引き起こします。
この問題を解決する方法の1つが NAPT(Network Address Port Translation) 、または IPマスカレード と呼ばれる技術です。NAPTでは、名前に「P(Port)」が含まれることからわかるように、ポート番号を使用します。
ポート番号には「送信元ポート番号」と「宛先ポート番号」が存在します。宛先ポート番号は、たとえばHTTPの場合は 80 がデフォルトですが、送信元ポート番号には特定の規則がありません。そこで、ランダムな送信元ポート番号を割り当てることにより、グローバルIPアドレスと組み合わせてコンピューターを特定できるようにしたのがNAPTです。
NAPTの技術により、リクエストを送ったコンピューターへレスポンスが正確に届けられます。
補足:ウェルノウンポート番号
ポート番号は通信プロトコルと密接に関連しています。一般的に使用される通信プロトコルにはデフォルトのポート番号が設定されており、そのポート番号から通信プロトコルを推測できます。
以下のようなポート番号を ウェルノウンポート番号(Well-known Port Number) と言います。「よく知られたポート番号」という意味です。
Well-known Port Number(ウェルノウンポート番号)
| 通信プロトコル | ポート番号 | プロトコルの使用目的 |
|---|---|---|
| FTP | 20, 21 | ファイル転送用 |
| SMTP | 25 | メール送信用 |
| HTTP | 80 | Web用 |
| POP | 110 | メール受信用 |
| NTP | 123 | 時刻同期用 |
| IMAP | 143 | メール受信用 |
| SSL(HTTPS) | 443 | 暗号化用 |
ウェルノウンポート番号は、正しい使用目的で使う場合、その記述を省略できます。
Lesson 3Chapter 7HTTP(HTTPS)
次にHTTPについて詳細を学びましょう。
- HTTPには、いくつかのバージョンが存在します。HTTP/2の普及が進んでいますが、ここではよりシンプルな仕様であるHTTP/1.1について説明します。
- 前述のとおり、HTTPSは、HTTPのセキュアなバージョンです。HTTPSは、通信を暗号化してセキュリティを強化しますが、基本的な通信の流れはHTTPに準じています。このため、HTTPの動作原理を理解することで、HTTPSの理解にも役立ちます。
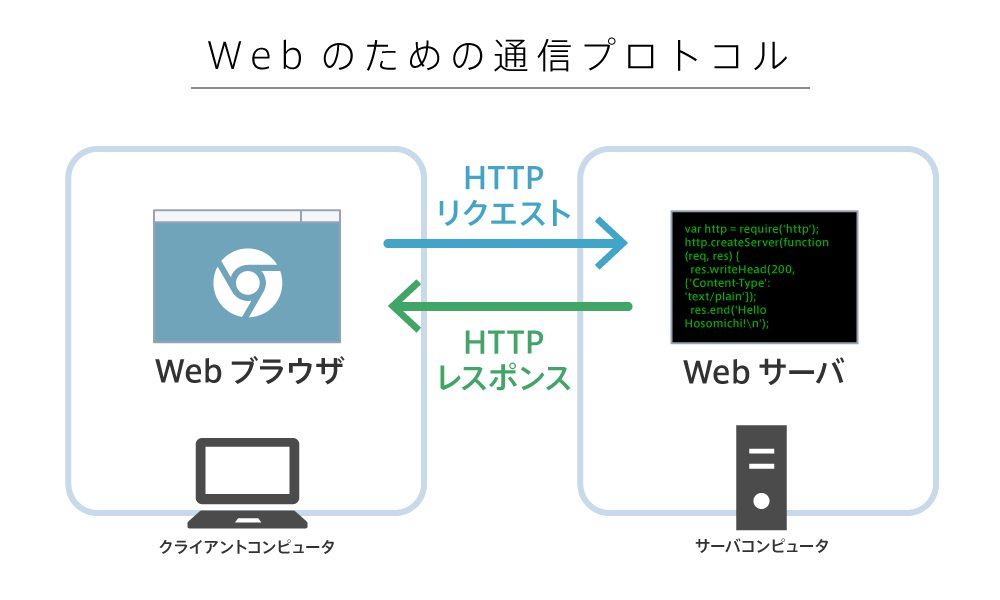
Lesson 3Chapter 7.1HTTPリクエストとHTTPレスポンス
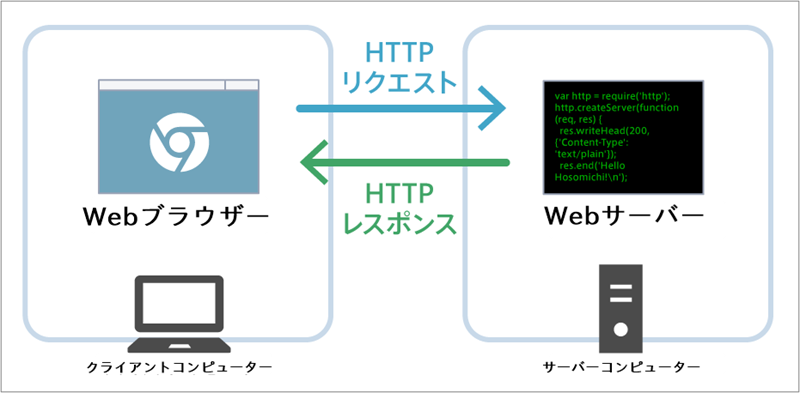
ブラウザがWebサーバーに対して送信するリクエストのことを「HTTPリクエスト」と呼び、WebサーバーがブラウザのHTTPリクエストに応答して返すレスポンスは「HTTPレスポンス」と呼ばれます。
- HTTPリクエスト:ブラウザがWebサーバーに対して送信するリクエスト
- HTTPレスポンス:Webサーバーがブラウザに返すレスポンス
HTTPリクエストメッセージの例
「HTTPリクエストを送信する」ということは、HTTPリクエストメッセージをWebサーバーに向けて送ることを意味します。
以下はHTTPリクエストメッセージの具体例です。 https://techacademy.jp のページから「利用規約」リンクをクリックし、 https://techacademy.jp/terms のWebページを表示する際に送信されるHTTPリクエストメッセージの例です。
GET https://techacademy.jp/terms HTTP/1.1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate, br, zstd
Accept-Language:ja,en-US;q=0.9,en;q=0.8
Cookie: ...=...; ...
HTTPリクエストメッセージの一般的な形式は以下の通りです。
HTTPリクエストメッセージの一般形式
メソッド URL HTTPのバージョン
ヘッダ部(付加情報)
(空行)
ボディ部
それぞれの部分を確認しましょう。
1行目
メソッド URL HTTPのバージョン
具体例の該当箇所は以下です。
GET https://techacademy.jp/terms HTTP/1.1
対比すると以下のようになります。
| 一般形式 | 具体例 |
|---|---|
| メソッド | GET |
| URLのパス | /common/terms/ |
| HTTPのバージョン | HTTP/1.1 |
GET は「読み込み」を意味するメソッドです。メソッドについては後ほど説明します。
GET /common/terms/ HTTP/1.1 で「指定されたURLのパスを、HTTPバージョン1.1で読み込む」という意味になります。
2行目以降
ヘッダ部(付加情報)
(空行)
具体例の該当箇所は以下です。
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate, br, zstd
Accept-Language:ja,en-US;q=0.9,en;q=0.8
Cookie: ...=...; ...
残りの行はさまざまな接続情報を含みますが、ここでは省略します。
HTTPリクエストメッセージでは、最後の空行でヘッダー部が終了します。
ボディ部に関する補足
今回の例では ボディ部 は存在しませんが、たとえばPOST(フォームデータを送信する際に使用するメソッド)の場合、ボディ部にはフォームデータが入り、リクエストとしてサーバーに送信されます。
このような形式でリクエストを送ることが、HTTPという通信規約(プロトコル)によって定められています。したがって、HTTPリクエストは常に上記の形式で通信します。すべてを完璧に覚える必要はありませんが、HTTPというWeb用の通信プロトコルでは、このような形式で通信が行なわれることを理解しておくと良いでしょう。
HTTPレスポンスメッセージの例
HTTPレスポンスを返すというのは、HTTPレスポンスメッセージをクライアントに向けて送るという意味です。
以下はHTTPレスポンスメッセージの具体例です。先ほどのHTTPリクエストメッセージに対するHTTPレスポンスメッセージの例です。
HTTP/1.1 200 OK
Content-Type: text/html
Content-Length: 43701
Connection: keep-alive
Last-Modified: Fri, 10 Nov 2023 02:50:16 GMT
(長いので省略)
Referrer-Policy: same-origin
Content-Security-Policy: default-src 'self';
X-Content-Type-Options: nosniff
Strict-Transport-Security: max-age=31536000
Vary: Origin
<!DOCTYPE html>
<html lang="ja" data-theme="techacademy" data-capo="">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>利用規約 |テックアカデミー</title>
(以下、Webページのコンテンツが続くので省略)
上記はHTTPレスポンスメッセージの具体例です。HTTPレスポンスメッセージの一般的な形式は以下の通りです。
HTTPレスポンスメッセージの一般形式
HTTPのバージョン ステータスコード ステータス
ヘッダ部(付加情報)
(空行)
ボディ部
それぞれの部分を確認しましょう。
1行目
HTTPのバージョン ステータスコード ステータス
具体例の該当箇所は以下です。
HTTP/1.1 200 OK
対比すると以下のようになります。
| 一般形式 | 具体例 |
|---|---|
| HTTPのバージョン | HTTP/1.1 |
| ステータスコード | 200 |
| ステータス | OK |
HTTPのバージョンが最初に来ているのは、以降のメッセージ形式を最初に知らせるためです。
ステータスコードは、リクエストに対してサーバーがどう反応したかを示す番号になり、今回の 200 であれば正常に動作したことを示します。また、ステータスコードと対応するステータスも文字列として返ってきます。200 の場合は OK の文字列になります。
2行目以降~空行まで
ヘッダ部(付加情報)
(空行)
具体例の該当箇所は以下です。
Content-Type: text/html
Content-Length: 43701
Connection: keep-alive
Last-Modified: Fri, 10 Nov 2023 02:50:16 GMT
(長いので省略)
Referrer-Policy: same-origin
Content-Security-Policy: default-src 'self';
X-Content-Type-Options: nosniff
Strict-Transport-Security: max-age=31536000
Vary: Origin
ヘッダー部では、サーバー情報やレスポンスデータの情報が記されています。今の時点で、それぞれの内容を理解する必要はありません。
HTTPレスポンスメッセージでも、最後の空行でヘッダー部が終了します。
ボディ部
ボディ部
具体例の該当箇所は以下です。
<!DOCTYPE html>
<html lang="ja" data-theme="techacademy" data-capo="">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>利用規約 |テックアカデミー</title>
(以下、Webページのコンテンツが続くので省略)
今回のボディ部は、GETメソッド(読み込み用メソッド)に対するレスポンスです。ブラウザはレスポンスとして送られてきたコンテンツ(HTML文書)を、Webページとして表示します。
以上がHTTPリクエストメッセージとHTTPレスポンスメッセージの概要です。
URLの最初にあるHTTPは、Web用の通信プロトコルを示していると覚えておきましょう。
Lesson 3Chapter 7.2HTTPリクエストの4つのメソッド
Webでは基本的に、あるリソースに対して4つのことが可能です。ここでいうリソースとは、Web上にあるWebページやデータのすべてです。たとえば、Yahoo! JAPANのニュース記事ページや、Facebookのコメント、X(Twitter)のポスト、ブログの記事やコメントなどです。
それらのリソースは基本的に4つの操作が可能です。それがCRUD(クラッド)と呼ばれる操作です。
4つの操作 - CRUD
CRUDは4つの操作の頭文字を取ったものです。
| 英語 | 日本語 |
|---|---|
| Create | 作成 |
| Read | 取得 |
| Update | 更新 |
| Delete | 削除 |
FacebookのコメントやX(Twitter)のポストについて考えてみます。
自分が今までに投稿したコメントやポストを閲覧するとき、Read(取得)の操作をします。投稿するときはCreate(作成)の操作をします。誤変換などを発見して修正したいときはUpdate(更新)の操作をします。そして「やっぱり、この投稿は要らない」と思ったらDelete(削除)の操作によって削除できます。
ただし、Yahoo! JAPANのニュース記事などユーザーが操作権限を持っていないリソースに対しては、Read(取得)以外の操作は許可されていません。
HTTPリクエストでのCRUD
WebはHTTPというWeb用のプロトコルによって通信を行ないます。HTTP通信におけるCRUDのための4つのメソッドを学びましょう。ここでいうメソッドは、方法論といった意味ではなく、単にHTTPリクエスト内でのCRUD操作をする際に使われる語句のことを言います。
HTTPリクエストメッセージ内では、CRUDのそれぞれに該当する下記の4つのメソッドが用いられます。
| 英語 | 日本語 | HTTPメソッド |
|---|---|---|
| Create | 作成 | POST |
| Read | 取得 | GET |
| Update | 更新 | PUT |
| Delete | 削除 | DELETE |
先ほどのHTTPリクエストメッセージの例をもう一度見てみましょう。
GET /ja/company/terms/ HTTP/1.1
Host: www.lycorp.co.jp
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36
Accept: */*
Accept-Encoding: gzip, deflate, br
Accept-Language: ja,en-US;q=0.9,en;q=0.8
Cookie: ...=...; ...
最初の行に GET /ja/company/terms/ HTTP/1.1 とあります。これは「/ja/company/terms/ というリソース(Yahoo! JAPANのニュース記事)に対して、 GET(Read、取得)操作を要求します」というHTTPリクエストになります。
GETだけではなく、あるリソースに対してCRUD操作をするとき、POST や PUT 、 DELETE も同様に、HTTPリクエストメッセージの中の最初の一行目に書かれます。
このようにブラウザとWebサーバーの間では、HTTPという通信プロトコルが利用され、HTTPリクエストとHTTPレスポンスというメッセージを送受信することで、リソースに対する操作を行なっています。これがWeb上の通信の実態です。
Lesson 3Chapter 8TCP/IPモデル
これまで以下の内容について学んできました。
- URL
- IPとDNS
- HTTP(HTTPS)
このなかで、通信プロトコルに分類されるのはIPとHTTPです。IPはインターネット接続を支える通信プロトコルで、HTTPは「IPに基づいて」アプリ同士(たとえばブラウザとWebサーバー)が通信するためのプロトコルです。
「IPに基づいて」という表現は、HTTPとIPではプロトコル階層が異なる という意味です。
以下で紹介する各種プロトコルは階層構造を持っており、その階層を TCP/IPモデル と呼んでいます。現在のインターネットを通じたアプリ間の通信は、このTCP/IPモデルという階層構造に基づいて成り立っています。
Lesson 3Chapter 8.1TCP/IPモデルの階層構造
TCP/IPモデルは4つの階層によって成り立っています。
| 階層 | プロトコル例 | 役割 |
|---|---|---|
| アプリケーション層 | HTTP, SMTP, POP, FTP, DNS, NTP等 | アプリ同士がデータをやり取りするための通信プロトコル群 |
| トランスポート層 | TCP, UDP | アプリが安定してデータを送受信できるように通信路を確保する |
| インターネット層 | IP等 | 複数のネットワークを相互に接続した環境(インターネット)で、個々のコンピューター間のデータ送受信を実現する |
| ネットワークインターフェイス層 | Ethernet, Wi-Fi等 | 物理的なネットワークインターフェイスとデータリンクプロトコルを通じて、ネットワーク間のデータ伝送を可能にする |
先ほど学んだHTTPはアプリケーション層の通信プロトコルで、IPはインターネット層の通信プロトコルとなります。
これらの階層は下層に行くほど物理的な通信インフラストラクチャ(ネットワークケーブルや無線接続など)に近くなり、上層に行くほど、ブラウザなどユーザーが直接操作するアプリの通信プロトコルに近くなります。
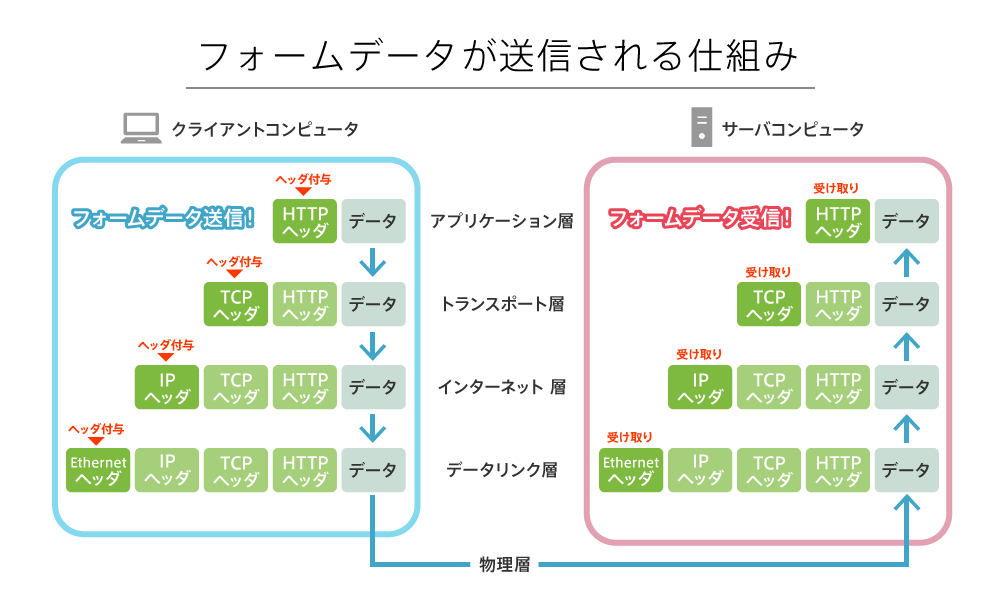
以下の図は「Webアプリでフォームデータを送信」することを例に、TCP/IPモデルの通信を表したものです。役割がわかりやすいよう、ネットワークインターフェイス層に含まれる「物理的なネットワークインターフェイス(物理層)」と「データリンクプロトコル(データリンク層)」を分けて表現しています。
Lesson 3Chapter 8.2アプリケーション層の役割
アプリケーション層は、実際にユーザーが使用するアプリの通信を可能にする ためのプロトコル群です。たとえば、HTTPはWebデータの送受信用プロトコルであり、SMTP、POP、IMAPはメール送受信用のプロトコルです。アプリによって送受信するデータの形式が異なるため、それぞれのプロトコルは別々に定義されています。
コンピューター同士の通信は、アプリケーション層の通信からスタートします。そのため、アプリケーション層はTCP/IPモデルのなかで最上位に位置します。
Lesson 3Chapter 8.3トランスポート層の役割
トランスポート層の役割は、通信路を確立してデータを通信相手に届ける ことです。
トランスポート層にはTCPとUDPの2つの主要なプロトコルがあります。
TCP
TCP(Transmission Control Protocol)は、コネクション型(接続指向型)の通信プロトコルであり、高い信頼性を持ち、確実にデータを届ける プロトコルです。しかし、この信頼性を確保するための手順が増えるため、通信開始までに時間がかかります。
HTTPは通常、TCPを使用して通信します。そのため「Webページ内の単語が一部表示されない」といったデータ受信の不具合は発生しません。データを確実にすべて届ける必要がある場合 にはTCPが使用されます。「TCP/IPモデル」の名前が示すように、一般的なインターネット通信ではTCPがトランスポート層のプロトコルとして採用されています。
UDP
UDP(User Datagram Protocol)は、高い信頼性を持ったTCPと違って、コネクションレス型(接続レス型)の通信プロトコルです。高速通信が可能 ですが、信頼性は低くなります。
UDPは、音声通話やビデオ通話など リアルタイム性を重視 して多少のデータ転送ミスを許容できる通信に使用されます。たとえば、ビデオ通話でときどき映像が止まったり音声の届かない場合がありますが、これはUDPがトランスポート層のプロトコルとして採用されているためです。
Lesson 3Chapter 8.4インターネット層の役割
インターネット層、とくに「IP」の主要な役割は、各コンピューターにIPアドレスを割り当てて、識別することです。IPアドレスを通じて、データを目的の通信相手まで転送します。
この機能を実現する主要な機器が ルータ です。
ルータはIP通信のための機器
あなたのコンピューターが属するプライベートネットワークの「グローバルIPアドレス(以下IPアドレスと表記)」は変更されることがあります。IPアドレスがいつ変更されるかは、インターネットサービスプロバイダー(ISP)との契約によって異なります。IPアドレスが日々変わることも珍しくはありません。
IPアドレスが変更されても、同じコンピューターへの通信が可能なのはルータのおかげです。
ルータは、異なるネットワーク間を接続する機器です。ルータはインターネット層(IP)の通信を支える重要な機器であり、インターネットへの接続を可能にしています。
ルータはIPアドレスを利用してデータを目的のコンピューターまで配送します。内部的には「ルーティングテーブル」と呼ばれるデータベースを使用して、宛先のIPアドレスに基づいてデータ転送のルートを決定します。IPアドレスが変更された場合、ルーティングテーブルの情報もそれに合わせて更新されます。
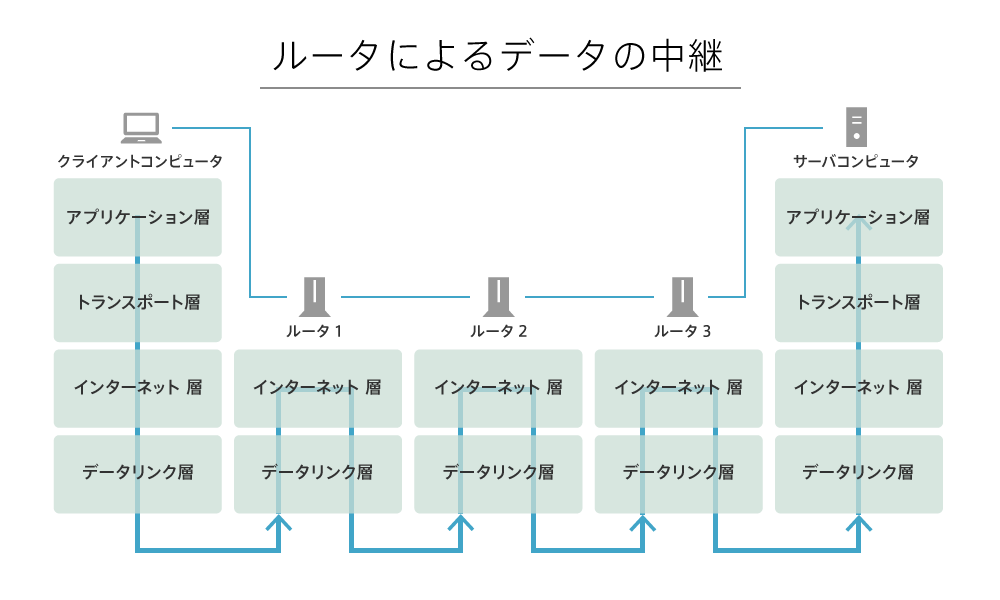
ルータはルータ同士やコンピューターに接続され、データを「バケツリレー方式」で転送します。以下の図で確認しましょう。
左側の「クライアントコンピューター」からデータが送信されると、最初の「ルータ1」がそれを受け取ります。ルータ1は、宛先のIPアドレスとルーティングテーブルを比較して、次に「ルータ2」へ送信すればよいということを判断します。
これを繰り返し、最終的に目的地の宛先IPアドレスを持つサーバーコンピューターにデータが届く、という仕組みになっています。
Lesson 3Chapter 8.5ネットワークインターフェイス層
ネットワークインターフェイス層は、データリンクプロトコル(データリンク層)と、物理的なネットワークインターフェイス(物理層)で構成されます。
データリンク層
データリンク層は、後述する「物理層」を通じて直接接続された機器間の通信を可能にします。
具体的には「LANボード(コンピューターに内蔵されている通信装置)」などの機器を制御・識別し、そのための伝送路を確保します。
物理層
物理層では、LANボードなどから送出されたデータを電気信号に変換し、ケーブルなどの物理的な伝送媒体を通じて送信する機能を提供します。
コンピューターのデータは、無線LANやLANケーブルを経由してルータに運ばれ、光ファイバケーブルなどを通じて外部ネットワークへと送出されます。そしてインターネットサービスプロバイダー(ISP)同士が接続された光ファイバケーブルなどを経由して、国内外のインターネットに伝送されます。
インターネット上のすべてのコンピューターは物理的に接続されているのです。
Lesson 3Chapter 8.6階層構造の役割
通信プロトコルの階層構造によって、役割が明確に分担され、各通信プロトコルが責任を持つ範囲が小さくなりました。これにより、各層は自分の役割以外の機能を下層のプロトコルに任せることができます。
たとえば、HTTPはアプリ間の通信にのみ集中します。通信路の確保はTCPに、インターネットへの接続はIPに、そして回線の接続状況はデータリンク層や物理層に完全に任せます。
また、階層化することで、1つの層の技術を他の層に影響を与えることなく改良することが可能というメリットもあります。
Lesson 3Chapter 9インターネットを活用したサービス
インターネットは、Webページ閲覧以外にも多種多様なサービスを提供します。

以下に代表的な例を挙げます。
メール(SMTP/POP/IMAP)
テキストメッセージや添付ファイルをやり取りする電子メールは、SMTP(送信)、POP、IMAP(受信)といった専用プロトコルで通信します。インターネットは、異なる場所や組織に属するメールサーバー間のメッセージ転送を可能にし、グローバルなコミュニケーションを支えます。
- 具体例:Gmail、Outlook、Yahoo!メール
オンライン会議・ビデオチャット
インターネット経由でリアルタイムに音声・映像をやり取りできます。Web会議ツールやチャットアプリが普及し、遠隔地からでも円滑なコミュニケーションが可能です。
- 具体例:Zoom、Microsoft Teams、Google Meet
クラウドストレージ・ファイル共有
データセンター上のサーバーへファイルをアップロードし、インターネットを通して世界中の拠点から同じデータへアクセスできます。これにより、離れた場所にいるチームメンバーとも共同作業が簡単になります。
- 具体例:Google ドライブ、Dropbox、Microsoft OneDrive、Box
ストリーミングサービス
インターネットを介して動画や音楽をリアルタイム再生できます。YouTubeやNetflix、Spotifyなどは、サーバーからユーザーへ連続的にデータを送信し、ダウンロードを待たずにコンテンツ視聴を可能にしています。
- 具体例:YouTube(動画)、Netflix(動画)、Amazon Prime Video(動画)、Spotify(音楽)、Apple Music(音楽)
SNS・オンラインコミュニティ
個人や組織が情報発信し、グローバルなコミュニティを形成できます。X(Twitter)やFacebook、InstagramなどのSNSは、インターネットを通じて世界の人々をつなぎ、情報共有を促進します。
- 具体例:X(旧Twitter)、Facebook、Instagram、LinkedIn、TikTok、Reddit
Lesson 3Chapter 10まとめ
このレッスンでは、ネットワークが単なる配線や接続ではなく、複数の層やプロトコル、さまざまな機器やサービスによって成り立つ仕組みであることを学びました。家やオフィスのLAN、世界規模のWAN、それらをつなぐインターネットの存在が、私たちの情報活用を飛躍的に広げています。
ネットワークの知識は、ビジネスや日常生活で重要な意味を持ちます。インターネットを介した情報交換や、クラウドサービスの活用を前提とした働き方が当たり前となるなか、ネットワークの基本を理解しておけば、変化に柔軟に対応できます。そして、新しい技術やサービスが登場しても、その仕組みを体系的に捉え、効果的に運用することができるようになるでしょう。
このレッスンで学んだこと
このレッスンで学んだことを振り返り、理解度を確認しましょう。
- ネットワークは、複数の機器を接続してデータを送受信する仕組みである。
- ネットワークは、家庭やオフィスなどのLANと、複数のLANを接続したWANがある。WANの代表がインターネットである。
- クライアントはサービスを利用する側、サーバーはサービスを提供する側として機能する。
- ルーターは異なるネットワーク間を接続してデータ転送経路を選択する機器である。
- 有線LANは、高速かつ安定した通信が可能で電磁干渉の影響が少ない一方、設置が手間で移動が制限される。
- 無線LAN(Wi-Fi)は電波を用いた接続で、ケーブル不要で移動や増設が容易だが、通信速度低下の可能性があり、セキュリティ面の対策も必要となる。
- URLはWeb上の特定のリソースを指定する「住所」に相当し、「プロトコル名・ホスト名・ドメイン名・ポート番号・パス」を組み合わせて表現する。
- IPアドレスはインターネット上でコンピューターを特定するための数値形式の「住所」である。
- DNSは、URL(ホスト名・ドメイン名)をIPアドレスに変換する仕組み。
- NATは複数のプライベートIPを1つのグローバルIPアドレスに変換してインターネットに接続する仕組み。
- HTTPはブラウザがWebサーバーへHTTPリクエストを送り、サーバーがコンテンツをHTTPレスポンスとして返す仕組み
- HTTPメソッドには、データ取得の
GET、データ登録のPOST、データ更新のPUT、データ削除のDELETEがある。 - HTTPSはHTTP通信を暗号化したプロトコルであり、SSL/TLS技術を用いてデータを暗号化する。
- TCP/IPモデルはアプリケーション層、トランスポート層、インターネット層、ネットワークインターフェイス層の4つの階層からなる。
- インターネット上のサービスには、Web、メール、オンライン会議ツール、クラウドストレージ、ストリーミング、SNSなどがある。
課題インターネット通信の仕組みを説明しよう
ブラウザで https://www.yahoo.co.jp というURLにアクセスするとします。このとき、Webページが表示されるまでの過程を時系列に説明してください。ただし、下記に指定した用語をすべて使用してください。
- ブラウザ
- DNS
- IPアドレス
- Webサーバー
- HTTPリクエスト
- HTTPレスポンス
課題の要件
説明は以下の書き出しからはめてください。
ブラウザで指定のWebページにアクセスするとき、
課題の提出
「課題を提出する」ボタンを押したら、コメントを入力できるウィンドウが出てきますので、そのコメント欄に解答を入力して、「提出する」ボタンを押して送信してください。メンターは、提出された解答内容をレビューします。