目次 - Lesson5
アルゴリズムとプログラミング
Lesson 5Chapter 1学習の目標
このレッスンでは、課題を段階的に整理して具体的な手順に落とし込む「アルゴリズム」と、それをコンピューターで実行するための「プログラミング」について学びます。
これまで学んだように、現代では顧客管理やデータ分析、在庫管理など、さまざまな場面でアプリケーションが活用されています。これらのアプリケーションを形作るスキルが、アルゴリズムとプログラミングです。
ビジネスパーソンにとっても、アルゴリズムやプログラミングを学ぶメリットは大きいです。
- 問題解決力や論理的思考力の強化
- 新しいビジネスチャンスの発見
- AIへの適切な作業指示
- 自分たちの業務に合わせたアプリケーションの作成
- エンジニアなどの専門家とのコミュニケーションの円滑化
プログラミングを学ぶことは、単にソースコードの書き方を覚えるだけではありません。その背後にあるプログラミング的な考え方や、アプローチの方法(アルゴリズム)を理解することが重要です。その上で、プログラミング言語での実装方法を学ぶことで、ビジネスの現場で汎用的に役立つ課題解決力を身につけることができます。このレッスンで、順番に学んでいきましょう。
本レッスンの主な内容
- プログラミング思考とアルゴリズム
- フローチャート入門
- さまざまなアルゴリズム
- プログラミング言語とは
- プログラミングを体験してみよう
- システムとプログラムの関係
本レッスンのゴール
アルゴリズムとプログラミングの基礎、システムとプログラムの関係を正しく理解すること
本レッスンの前提条件
- ビジネスパーソンに必要なITスキルを把握していること(レッスン1)
- コンピュータの中身について正しいイメージを持っていること(レッスン2)
- ネットワークとインターネットの基本的な仕組み、関連技術、およびそれらがどのようにつながり合っているかを正しく理解していること(レッスン3)
- 情報資産を守るための情報セキュリティの基本概念と3要素、リスク評価、脅威・対策技術、法規制を正しく理解していること(レッスン4)
Lesson 5Chapter 2プログラミング思考とアルゴリズム
プログラミング思考 とは、プログラムを書く前に行なう「問題解決のための考え方」のことです。
プログラミングを行なう際、最初からいきなりソースコードを書くのは難しいものです。しかし、プログラミング思考をもとに問題を論理的に分解し、順序立てて解決策(アルゴリズム)を見つける方法を理解しておくと、プログラミングをよりスムーズに進めることができます。
- 問題を論理的に分解する
- コンピューターが処理できる形式で表現する
- アルゴリズム
- プログラミング思考のメリット
順番に確認していきましょう。
Lesson 5Chapter 2.1問題を論理的に分解する
最初に、大きな問題を小さなサブタスクに分解します。大きな問題は、そのままでは解決が難しいですが、小さなサブタスクに分解して順番に解決することで、最終的に全体の問題を解決できます。

以下のように進めると良いでしょう。
- ゴールを明確にする
- 目的:何のためにプログラムを作るのか?
- ゴール:処理を終えたとき、どのような状態になっているのが理想か?
- 入力と出力を定義する
- 入力:このプログラムが受け取るデータは何か?
- 出力:このプログラムが最終的に返す答えは何か?
- 手順をざっくり考える
- 始めにどんな作業が必要か
- 中間でどういう作業をするか
- 最終的に出力をどう作るか
- 処理の順序や関係性を確認する
- どの作業とどの作業が関連しているか
- どちらの処理を先に行なう必要があるか
- 並行してできる作業はあるか
実際に試してみよう
例えば「送料込価格を計算する」という問題があるとします。問題の内容は以下の通りです。
- 税抜価格をもとに、消費税込の価格と送料を合計した「送料込価格」を計算して表示するソースコードを作成してください。税込価格が2000円以上の場合は送料無料、2000円未満の場合は350円とします。消費税率は10%です。
この問題に対して、最初からいきなりソースコードを書くのは難しいでしょう。そこで、まずは問題を小さなサブタスクに分解します。分解結果は以下のようになります。
- 税抜価格を入力する
- 税込価格を計算する
- 送料を計算する
- 税込価格が2000円以上の場合は送料無料
- 税込価格が2000円未満の場合は送料350円
- 「送料込価格は○○○円です」と表示する
大きな問題を分解することで、1つ1つのサブタスクで行なうことが、明確になりましたね。
Lesson 5Chapter 2.2コンピューターが処理できる形式で表現する
次に、サブタスクをコンピューターが処理できる形式で表現します。
コンピューターは非常に単純で、「データを受け取って、加工し、出力する」ことしかできません。この仕組みを組み合わせることで、すべての処理を表現します。

以下のように進めると良いでしょう。
- データを整理する
- 「数値」や「文字列」、「真偽値(true/false)」のような、コンピューターが扱いやすい形に整理する
- 例:人間向けの情報:「誕生日」→ コンピューターが扱いやすい形:「年・月・日をそれぞれ数値で保持」
- データをどう保存し、どんなときに参照するのかをイメージするとスムーズ
- ルールや手順をコンピューターが理解できる形にする
- 自然言語の曖昧な表現を、コンピューターが理解できる「厳密な手順」にする
- 後述するフローチャートが有用
- 「制御構文」を意識する
- 分岐:もし(条件)ならこうする
- 繰り返し:(条件)が成立する限り繰り返す
Lesson 5Chapter 2.3アルゴリズム
アルゴリズム は「問題解決の手順」を意味します。プログラミングにおいては、入力データを所定のルールで処理し、最終的に望む結果を出すまでの一連の流れを指します。
プログラミング思考で整理した「データを受け取って、加工し、出力する」流れを整理したものがアルゴリズムです。重要な要素は以下です。
- 制御構文:プログラムの流れを制御する仕組み
- 変数:データを保存する箱
- 配列:同じ種類のデータをまとめて管理する仕組み
制御構文
制御構文 とは、プログラムの流れを制御するための基本的な仕組みです。制御構文には「逐次処理、条件分岐、繰り返し」の3種類があります。
- 逐次処理 :命令を順番に上から下へ実行する処理です。最も基本的な処理方法であり、プログラムを「1つずつ順に」実行していくことを意味します。
- 条件分岐 :「もし○○ならば△△をする、そうでなければ□□をする」といったように、条件に応じて異なる処理を実行する方法です。これにより、プログラムは状況に応じて異なる動作をします。
- 繰り返し :同じ処理を何度も繰り返すための仕組みです。繰り返し処理は、同じ作業を自動化したり、大量のデータを効率よく処理するために使います。

変数
変数 はデータを一時的に保存する箱のようなものです。コンピューターは、人間のように抽象的な情報を覚えておけないため、はっきりとした置き場である変数が必須となります。変数は、データを加工した結果をあとで使いたい場合に使用します。
配列
配列 は、同じ種類のデータをまとめて扱うための箱の集まりです。繰り返しと組み合わせて使うと、同じ処理を一括で行なうことができます。
実際に試してみよう
先ほどの「送料込価格を計算する」問題を、コンピューターが処理できるアルゴリズムとして表現してみましょう。それぞれのサブタスクは「データを受け取って、加工し、出力する」流れで考えます。また、データを加工した結果をあとで使いたいサブタスクでは変数を使用します。【】 で囲った部分が変数です。
- 【税抜価格】に、入力された値を代入する
- 【税込価格】に、【税抜価格】x 1.1を代入する
- 【送料】を計算する
- もしも、【税込価格】が2000円以上なら、【送料】に0円を代入する
- そうでなければ、【送料】に350円を代入する
- 「送料込価格は 【税込価格】+ 【送料】円です」と表示する
税抜価格や税込価格、送料は、あとの処理で使うので、変数に代入しています。送料込価格は表示するだけで、あとの処理では使わないため、変数には代入していません。
Lesson 5Chapter 2.4プログラミング思考のメリット
プログラミング思考を身につけると、以下のようなメリットが得られます。
- 課題解決能力が高まる
課題を明確に定義し、必要に応じて分割して検討する習慣が身につきます。視点が散漫になることを防ぎ、重要度に応じて優先順位をつける思考が自然と鍛えられます。 - 論理的思考力が付く
やみくもに実装を始めるのではなく、前提条件やゴールをはっきりさせるため、論理的な根拠に基づいて「何を」「どの順番で」「どう実行するか」を考えるようになります。これは日常のビジネスシーンでも役立つ思考法です。 - プログラミング思考で整理した手続きは自動化が容易
課題解決の流れとデータ処理の段取りを明確にし、コンピューターに指示を出す形まで落とし込めば、あとはプログラムやツールで自動化しやすくなります。特に繰り返し作業や大量データの処理は、ミスを減らしつつスピードも向上するため、ビジネス上の効率化につながります。
プログラミング思考を身につけるための練習方法
プログラミング思考は、身近なテーマで身につけることが可能です。
- 身近な作業を分解してみる
- 例:料理の手順、引っ越しの荷造りなど
- ステップごとに「材料(入力)」「道具(中間データ)」「完成物(出力)」を明確化し、どの手順をいつ行なうかを考える
- 紙に箇条書きで整理する
- 書くことで、処理の抜け漏れや矛盾に気づきやすくなる
- 「もしこのときに材料Aが不足していたらどうする?」といった条件分岐を意識できる
- 簡単な問題をフローチャートで書く
- 「数値の合計を求める」「合計を個数で割って平均を出す」など
- 実際にコードを書く前に、箇条書きやフローチャート(後述)で流れを整理する
- 他人に説明してみる
- 自分以外の人に手順を説明して、理解してもらう
- 質問や指摘を受けることで、曖昧な部分が見えてくる
Lesson 5Chapter 3フローチャート入門
フローチャート は、タスクの手順やデータの流れを「記号」と「矢印」で表現する方法です。複雑な処理や複数の選択肢がある場合でも、図形や分岐線を使うことで可視化できるため、多様な業務やプログラミングの場面で利用されています。
フローチャートの例:
前のチャプターで取り上げた「プログラミング思考」において、タスクをいかに分解し、どの順序で処理すべきかを考えることが重要とお伝えしました。フローチャートを用いると、このプロセスを誰が見てもわかる形で可視化できます。
ここでは、フローチャートのメリットと作図ツール、基本的な記号や構造、そして実際の書き方について確認します。
- フローチャートを使うメリット
- フローチャート作成ツール
- フローチャートの基本ルール
- 実際に書いてみよう
- 業務フローの表現
Lesson 5Chapter 3.1フローチャートを使うメリット
フローチャートには、以下のようなメリットがあります。
- 処理やタスクの全体像が把握しやすい
矢印でつながれた一連の流れを上から下、または左から右にたどることで、どこで何が起きているかをひと目で理解できます。文章や口頭の説明では理解しにくい段取りも、フローチャートなら視覚的にとらえやすくなります。 - 問題点や改善箇所を発見しやすい
手順を逐一図で示すことで、無駄なルートや条件分岐の漏れなどが可視化されます。フローを追っていると「ここの処理が曖昧」「ここでエラーが発生したらどうするか」などの疑問点を自然に洗い出せます。 - 共通言語として活用できる
フローチャートには国際標準の記号があります。チームメンバーや社外の協力会社など、背景や専門知識が異なる人同士でも、この共通の記号と流れに従えば誤解を少なくできます。マニュアル作りやシステム要件定義にも役立ちます。
Lesson 5Chapter 3.2フローチャート作成ツール
フローチャートを作成するには、以下のようなツールを使うと便利です。
PowerPointなどのオフィスソフト
PowerPoint や Google Slide などのオフィスソフトを使う場合は、「挿入」タブの「図形」メニューから「フローチャートの記号」を選んで配置し、カギ線コネクタなどの矢印を使って手順をつなぎます。オフィスソフトはビジネスの現場で広く使われているため、誰でも気軽に始められます。
オンラインツール(draw.io、Lucidchartなど)
ブラウザ上で利用できるサービスが多く、インストール不要で共同編集もしやすいのが特徴です。基本的なフローチャート記号だけでなく、さまざまなテンプレートやオブジェクトが用意されているため、プロ並みの図を簡単に作れます。
- draw.io :無料で利用可能。Google Drive等との連携が充実しています。
- Lucidchart :チーム内コラボがしやすい設計。UIがわかりやすく多機能です。
- Visio :有償ソフトですが、多彩な機能を備えているため、複雑な業務フロー図やネットワーク構成図などを本格的に描きたいときに適しています。Office製品との連携もスムーズです。
エディタの拡張機能
プログラミングで良く使われる VS Code というエディタの拡張機能を使うと、テキストベースでフローチャートを記述できます。
記述にはMermaidやplantumlなどの記法が用いられます。
テキストで記述したフローチャートの例(Mermaid形式):
graph TD
Start[開始] --> Step1[ステップ1: 作業を開始]
Step1 --> Step2{条件を満たしているか?}
Step2 -- はい --> Step3[次のステップを実行]
Step2 -- いいえ --> Step4[条件を再確認]
Step4 --> Step1
Step3 --> End[終了]
Lesson 5Chapter 3.3フローチャートの基本ルール
フローチャートでは、処理の開始・終了、判断、入出力などに対応した記号を使います。

一般的に、フローチャートは上から下へ向かって処理を並べます。左右に広げて描く場合もありますが、最終的にはどこかでゴール(終了)にたどり着く線形構造が基本です。分岐がある場合は、判断の記号(ひし形)を使って「Yes」「No」のようにルートを分けます。
Lesson 5Chapter 3.4実際に書いてみよう
先ほどの「送料込価格を計算する」問題のアルゴリズムを、フローチャートで表現してみましょう。
アルゴリズム
「送料込価格を計算する」問題のアルゴリズムを再掲します。
- 【税抜価格】に、入力された値を代入する
- 【税込価格】に、【税抜価格】x 1.1を代入する
- 【送料】を計算する
- もしも、【税込価格】が2000円以上なら、【送料】に0円を代入する
- そうでなければ、【送料】に350円を代入する
- 「送料込価格は 【税込価格】+ 【送料】円です」と表示する
フローチャートで記述する
フローチャートで表現すると、以下のようになります。
とても、わかりやすく表現できましたね。
Lesson 5Chapter 3.5業務フローの表現
フローチャートでは、より抽象度の高い業務フロー(業務の流れ)も表現できます。
例
ECサイトでの注文受付から発送までの業務フロー
問題を論理的に分解する
ECサイトでは、お客さまが注文を行なってから実際に商品の発送準備が完了するまで、いくつかのステップが存在します。一連のフローを大まかに整理してみましょう。
- 注文情報の取得
- お客さまがサイト上で注文する際、カートに商品を入れ、注文フォームに必要事項を入力します。
- このとき、商品名・数量・配送先情報・決済方法などが入力されます。
- 在庫確認
- システムは注文内容と在庫状況を照合します。
- 在庫が不足している場合は、欠品処理や別途手配のフローに進む必要があります。
- 注文確定・決済
- 在庫が確認できたら、注文が確定されます。
- クレジットカードなど、実際の決済処理を行ない、決済結果を受け取ります。
- 決済に失敗した場合は、再決済手続きや注文キャンセルの判断が必要です。
- ピッキング・梱包準備
- 倉庫などで、受注データをもとに実際の商品をピッキング(取り出し)します。
- 同時に、梱包作業の準備を行ない、送り状を発行します。
- 配送手続きの実施(発送準備完了)
- 配送業者に集荷を依頼し、確定した送り状・伝票とともに発送の準備を行ないます。
- 商品が実際に倉庫から出荷される前に、最終確認(品質チェックなど)を行なう場合もあります。
フローチャートで記述する
フローチャートで記述してみましょう。
このように、複数のタスクが含まれる業務フローも、フローチャートで整理するとわかりやすくなります。
Lesson 5Chapter 4さまざまなアルゴリズム
アルゴリズム は、問題を解決するための明確な手順を指します。
私たちが日常で行なう作業のなかにも、小さなアルゴリズムが数多く存在しています。たとえば「財布の中から小銭を取り出して合計金額を計算する」「本棚に並んだ書籍をあいうえお順に並べ替える」といった流れも、立派なアルゴリズムです。
プログラミングにおいては、この手順をコンピューターが実行できる形でコーディングし、入力から出力までを効率よく処理することが求められます。どのようなアルゴリズムを選ぶかで、処理の速度やメモリ使用量といったパフォーマンスが大きく変わります。取り扱うデータが増えれば増えるほど、アルゴリズムの優劣が結果に大きく影響するのです。
ここでは、代表的なアルゴリズムを確認し、効率性やプログラム全体に与える影響について整理します。
- 代表的なアルゴリズム
- 合計値を計算する
- 平均値を計算する
- 最大値・最小値を求める
- 偶数・奇数を判定する
- 文字列を反転(リバース)する
- 線形探索(リニアサーチ)
- バブルソート
- 素数判定
- アルゴリズムがプログラム全体に与える影響
- 参考:アルゴリズムの効率性と計算量
Lesson 5Chapter 4.1合計値を計算する
数値の配列を入力し、それらの合計値を求めます。
処理の流れ
配列の要素を1つずつ取り出して加算していくのがポイントです。
- 配列を用意する
- 初期値(sum=0)をセット
- 配列の要素を1つずつ取り出す
- sum に要素を加算
- すべての要素を処理し終えたら合計(sum)を出力
フローチャート
Lesson 5Chapter 4.2平均値を計算する
数値の配列を入力し、合計値を求めてから、要素数で割り平均値を算出します。
処理の流れ
配列の要素を1つずつ取り出し、合計(sum)に加算するとともに、要素数(count)にも1を加算するのがポイントです。
- 配列を用意する
- 初期値(sum=0、count=0)をセット
- 配列の要素を1つずつ取り出して合計(sum)と要素数(count)を算出
- 合計(sum)を要素数で割る
- 結果として平均値を出力
フローチャート
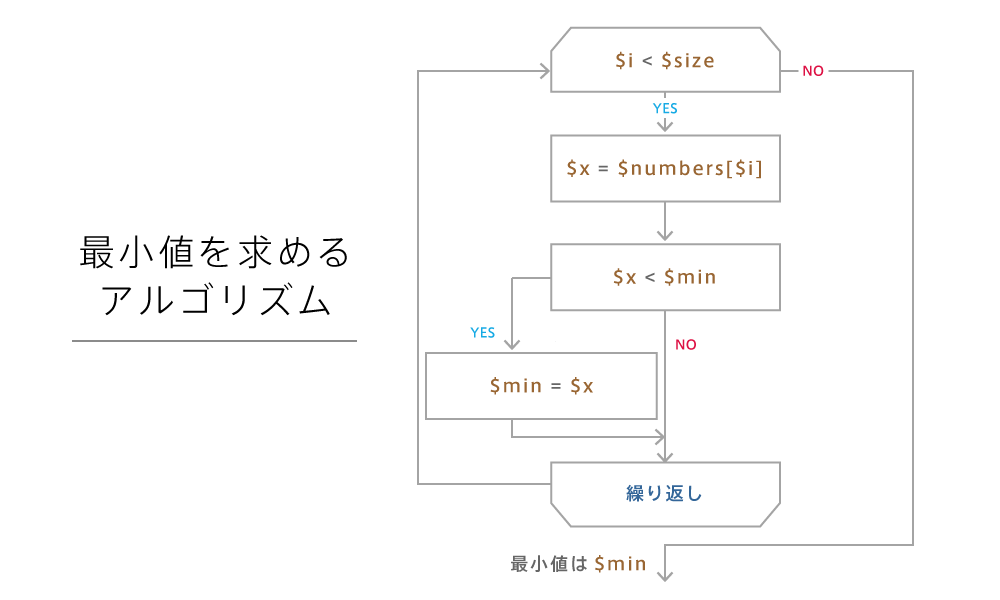
Lesson 5Chapter 4.3最大値・最小値を求める
数値の配列を入力し、全要素の中から最大値(または最小値)を見つけます。
処理の流れ
配列の最初の要素を初期値とし、配列の要素を1つずつ取り出して、より大きい(または小さい)値が見つかれば更新するのがポイントです。
- 配列を用意する
- 初期値(maxValue=配列の最初の要素など)をセット
- 配列の各要素と maxValue を比較
- より大きい(または小さい)値が見つかれば更新
- すべての要素を比較し終えたら最大値(最小値)を出力
フローチャート
ここでは最大値版を示します。最小値の場合は 要素 > maxValue? を 要素 < minValue? に変えるだけです。
Lesson 5Chapter 4.4偶数・奇数を判定する
入力された整数が「偶数か、奇数か」を判定します。
実際の処理としては「入力数 % 2 == 0 なら偶数、そうでなければ奇数」とします。
処理の流れ
剰余で判定するのは「整数」や「ある数の倍数」などの判定にも応用できます。
- 整数を入力
- 整数を2で割った余り(剰余)を計算
- 余りが0であれば偶数、そうでなければ奇数
- 結果を出力
フローチャート
繰り返しはないため、単純なフローです。
Lesson 5Chapter 4.5文字列を反転(リバース)する
文字列を後ろから読み取って、新しい文字列として構成し直します。
処理の流れ
- 文字列(str)を入力
- 出力用の空文字列(reverseStr)を初期化
- 文字列の末尾から先頭に向かって1文字ずつ取り出す
- 取り出した文字を reverseStr に追加していく
- 最後に reverseStr を出力
フローチャート
Lesson 5Chapter 4.6線形探索(リニアサーチ)
配列の先頭から1つずつ順番に探していきます。目的の要素を見つけたら処理を終了し、見つからなければ配列の末尾まで続けます。実装が容易ですが、最悪の場合、全要素を調べるため、データ数が多くなると時間がかかります。
処理の流れ
- 配列と探したい値(target)を用意
- 配列の先頭から順に要素を取り出す
- 要素 == target かを比較
- 一致したら「見つかった」旨を出力して探索終了
- 最後まで探して見つからなければ「見つからなかった」と出力
フローチャート
参考:二分探索(バイナリサーチ)
あらかじめ配列がソートされていることを前提に、要素を中央で半分に分けて、探索対象がどちらのグループに含まれるかを判定します。不要な半分を切り捨てて、残りの半分を再び二分して調べる操作を繰り返します。データ数が n の場合、探索にかかる手順は最大でも log2(n) 程度に抑えられ、線形探索よりも高速なことが多いです(ただし、ソートが必要な点にも注意)。
Lesson 5Chapter 4.7バブルソート
隣同士の要素を比較し、大きい(あるいは小さい)方を後ろ(または前)へ入れ替えていくことで、配列全体をソートします。
バブルソートは、配列を何度も走査し、隣接する2つの要素を比較しながら並べ替えます。隣り合う要素が逆順なら交換し、これを配列の末尾まで行なったあと、もう一度先頭からやり直すのを必要回数繰り返します。理解しやすい反面、大量データにはあまり効率的ではありません。
処理の流れ
- 配列を用意
- 配列の先頭から順に隣同士の要素を比較
- 順序が逆であれば要素を入れ替える
- 1回の走査が終わったら、末尾の要素が正しい位置(最大値)になる
- これを必要な回数(配列の長さ-1 など)だけ繰り返す
- すべての走査が終了したら、ソート完了
フローチャート
バブルソートは「外側ループ」と「内側ループ」の2重ループになります。
参考:クイックソート
分割統治法(Divide and Conquer)の一種です。基準となる要素(ピボット)を決め、そこより小さい要素と大きい要素を分割し、それぞれのグループに対して再帰的に同じ処理を繰り返すことでソートを進めます。うまくいけば高速に処理が進みますが、データの状態によっては性能が落ちることもあります。
Lesson 5Chapter 4.8素数判定
入力された整数が素数かどうかを調べます。素数判定には以下のルールがあります。
- 素数とは、 より大きく、 とその数自身以外で割り切れない数です。
- の場合は素数ではありません。
- の素数判定には から までではなく、 から までのループで十分です。
処理の流れ
- 整数(n)を入力
- i=2 から まで繰り返し処理
- n % i == 0 の場合、素数ではないと判断して終了
- すべての i で割り切れない場合は素数と判断する
- 結果を出力
フローチャート
Lesson 5Chapter 4.9アルゴリズムがプログラム全体に与える影響
プログラムは、ユーザーからの入力や外部システムからデータを受け取り、アルゴリズムに従って処理を進め、最終的に出力を生成します。そのため、アルゴリズムの選択や設計は、プログラム全体のパフォーマンスやメンテナンス性を左右します。
- 処理速度
特定のアルゴリズムが予想以上に時間を要する場合、ユーザーが操作を待たなければならなくなったり、夜間バッチの所要時間が伸びたりします。ビジネスにおいて処理時間はコストに直結するケースもあり、非効率なアルゴリズムが原因で大きな損失を生む可能性があります。 - メモリ使用量
ソートや探索のアルゴリズムによっては、一時的に大量のメモリを必要とするものがあります。メモリが逼迫すると、他のサービスのパフォーマンスにも悪影響を及ぼします。 - 保守性や拡張性
無理に複雑なアルゴリズムを導入すると、ソースコードが読みにくくなり、修正やバグ対応に時間がかかります。逆に、適切なアルゴリズムを選ぶことで、プログラムが長期的に保守しやすくなります。性能と可読性のバランスを考慮した選択が重要です。
Lesson 5Chapter 4.10参考:アルゴリズムの効率性と計算量
アルゴリズムの良し悪しを数値化して比較するために、Big-O表記(オーダー表記)という概念が用いられます。これは、データ数 n に対するアルゴリズムの処理ステップが、どの程度増加するかを大まかに示す記号です。たとえば、要素をすべて調べる探索の計算量は O(n)、二分探索は O(log n)、バブルソートは最悪で O(n^2) などと表現されます。
例:1000人の名簿から特定の人を探す
- 線形探索:最悪の場合、1000回調べないと見つからない可能性があります(
O(n))。 - 二分探索:あらかじめ名簿が姓やIDで並んでいれば、半分ずつ捨てながら探索を進められるため、
log2(1000)回程度の比較で済みます(およそ10回程度)。
データ量が膨大になると、この差が圧倒的な時間の開きとなります。したがって、プログラムのパフォーマンスを考えるうえで「どのくらいの計算量がかかるのか」を意識することは非常に重要です。
短期間での開発を優先して単純なアルゴリズムを採用する場合もあれば、将来的な拡張性を重視して高速なアルゴリズムを組み込むケースもあります。状況に応じて最適な選択を行なうためにも、アルゴリズムの基礎を理解することが大切です。
Lesson 5Chapter 5プログラミング言語とは
プログラミング言語 は、コンピュータに指示を与えるために使用される人工的な言語のことです。
レッスン2で学んだように、プログラムは通常、「高水準言語」と呼ばれる、人間にとって理解しやすい表現を用いるプログラミング言語で書かれます。プログラミング言語は、私たちが考えたアルゴリズムを、コンピューターが理解できる形へ変換するための手段となります。
- アルゴリズム:何をどう処理するかを示す設計図
- プログラミング言語:設計図を実際に動く形に落とし込むための文章
プログラミング言語には、さまざまな種類があります。ビジネスアプリケーションを支えるものから、Webサイトの動的な演出を担うもの、機械学習分野を得意とするものなど、用途によって最適な選択肢が異なります。
ここでは、プログラミング言語の仕組みや代表的な言語、コードを読みやすく保守しやすくする工夫、ソースコードをチームで管理する方法などについて確認します。
- プログラミング言語の仕組み
- 代表的なプログラミング言語
- コードの読みやすさと保守性
- バージョン管理の概要
Lesson 5Chapter 5.1プログラミング言語の仕組み
プログラミング言語は、大きく分けて「コンパイル型言語」と「インタプリタ型言語」に分類できます。
両方とも、人間が記述したソースコードを、コンピューターが理解できる形(機械語)に変換しますが、その変換方法に違いがあります。
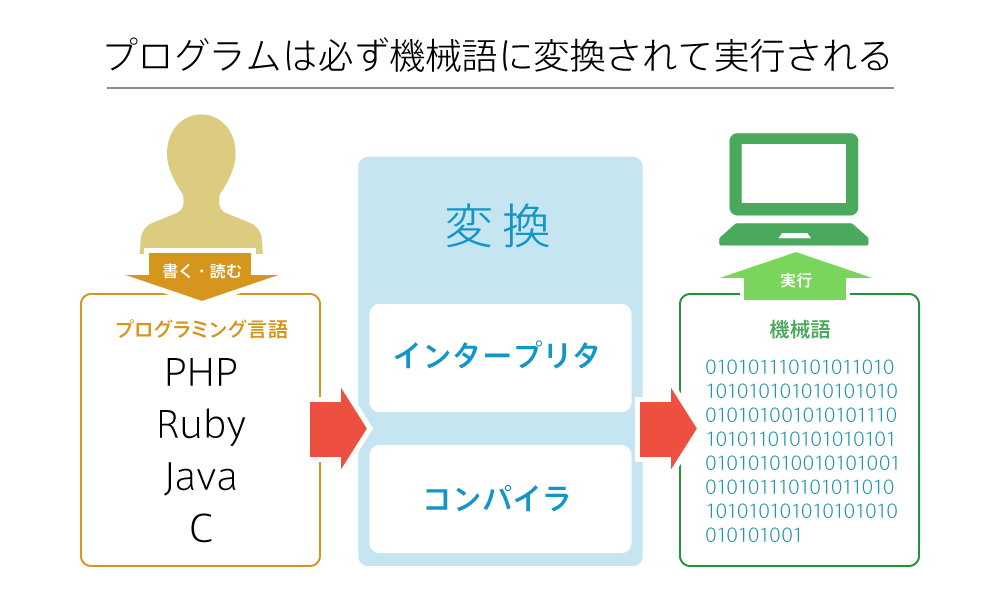
ソースコードと実行ファイルの違い
最初に、「ソースコード」と「実行ファイル」の違いを押さえておきましょう。
ソースコードは、プログラミング言語で書かれたテキスト形式の「指示書」です。以下のように英単語や記号を使って、コンピューターに行なってほしい処理を記述します。
Pythonのソースコードの例:
a = 5 b = 3 result = a + b print(f"足し算の結果: {result}")
ソースコードは人間が読める形ですが、そのままでは、コンピューターは理解できません。そこで、ソースコードを機械語へ変換してコンピューターが実行できる形にする必要があります。
コンパイル型言語
コンパイル型言語 は、「コンパイラ」と呼ばれるソフトウェアを使って、ソースコードを機械語に一括して変換(コンパイル)して「実行ファイル」を生成します。
変換後の実行ファイルは、拡張子が .exe や .out などのファイルとなり、これをダブルクリック(またはコマンド)で実行します。
- 代表例
C言語、C++、Java(※)、Go など
※Javaは、中間言語(バイトコード)へのコンパイル後にJVMがインタプリタのように動作するため、コンパイル型とインタプリタ型の両方の特徴を持ちます。 - メリット
- 実行速度が速い
機械語に変換された実行ファイルは、CPUが直接理解できるため、高速に動作します。 - 実行時のオーバーヘッドが少ない
すでにバイナリ化(機械語化)されているため、実行開始も軽量です。 - ソースコードの秘匿性
実行ファイルだけを配布すればよいため、ソースコードを公開しなくて済む場合があります。
- 実行速度が速い
- デメリット
- コンパイル時間がかかる
ソースコードを修正するたびにコンパイルをし直す必要があります。 - 実行ファイルがプラットフォーム依存
OSやCPUの種類に合わせてコンパイルし直さなければならないことが多いです。
- コンパイル時間がかかる
インタプリタ型言語
インタプリタ型言語は、ソースコードを「インタプリタ」と呼ばれるソフトウェアが読み取り、逐次(その場で)機械語に変換して実行する方式です。
コンパイル型言語のような「実行ファイル」は生成せず、代わりに、インタプリタを通してソースコードを動かすイメージです。
- 代表例
Python、Ruby、JavaScript、PHP など - メリット
- 開発効率が高い
ソースコードを変更してすぐに実行でき、コンパイルが不要なので試行錯誤しやすいです。 - 移植性が高い
同じソースコードを、対応するインタプリタがあればさまざまな環境で動かせます。 - 実行時に柔軟な処理が可能
実行中にコードを生成・実行する、動的な型付けを行なうなど、柔軟に対応できます。
- 開発効率が高い
- デメリット
- 実行速度が遅くなりがち
毎回ソースコードを解釈しながら動作するため、コンパイル型言語より遅くなる場合があります。 - 配布時にソースコードが露出しやすい
実行ファイルとしてまとめられず、コードをそのまま提供するケースが多いため、ソースコードが外部に見えやすい傾向にあります。
- 実行速度が遅くなりがち
Lesson 5Chapter 5.2代表的なプログラミング言語
プログラミング言語は用途や設計思想によって多岐にわたります。主なプログラミング言語を紹介します。
Python
データ分析や機械学習、Web開発など幅広い分野で利用されます。シンプルな文法と豊富なライブラリが魅力で、初心者にも取り組みやすい言語です。インタプリタ型であるため、対話型の開発・実験がしやすく、AIやサーバーサイドなどの領域で盛んに使われています。
Java
業務システムやAndroidアプリ開発などで根強い人気を持つコンパイル型言語です。オブジェクト指向の思想がしっかり組み込まれ、規模の大きいプロジェクトでも保守しやすいとされています。動作環境として「JVM(Java仮想マシン)」があり、一度コンパイルしたコードはさまざまなOSで実行可能です。
C++
速度やメモリの制御がシビアな分野(ゲーム開発、組込みシステム、高性能計算など)で広く利用されるコンパイル型言語です。C言語の後継としてオブジェクト指向やテンプレート機能を追加しており、優れた実行性能を発揮します。その反面、文法が複雑で学習コストが高めです。
JavaScript
ブラウザ上で動作するスクリプト言語として発展してきました。HTMLやCSSと組み合わせ、Webページを動的に制御する用途で用いられます。現在ではサーバーサイドの Node.js 環境でも動作し、フルスタック開発が可能な言語になりました。
HTML・CSS(マークアップ言語)
これらは厳密にはプログラミング言語ではありませんが、Web開発において欠かせない要素です。HTML はページの構造や要素を定義し、CSS は見た目の装飾を担当します。ロジックを記述するものではないため、たとえばループや条件分岐などは持ちませんが、JavaScriptと組み合わせてWebアプリを構築する際に重要です。
これら以外にも、Ruby や Go、Rust など、注目される言語は数多くあります。プロジェクトの目的やチームのスキルセットによって選択は異なるため、「人気があるから」という理由だけで決めるのではなく、保守性や将来性、コミュニティの活発さなどを総合的に評価することが大切です。
Lesson 5Chapter 5.3コードの読みやすさと保守性
プログラミング言語を選んだとしても、誰もがすぐ理解できるコードになるとは限りません。「コードの書き方やスタイル」は読みやすさに大きく影響します。複数の開発者が参加するプロジェクトでは、共通のコーディング規約や命名規則などを決めておくことが一般的です。
コーディングスタイル
コーディングスタイル とは、ソースコードを書く際の一貫性のあるルールやガイドラインのことです。これにより、コードの可読性や保守性が向上し、複数の開発者が協力して作業する際に混乱を避けることができます。
コメントやドキュメントの活用
ソースコード内に、「この変数はなぜ必要なのか」「なぜこのアルゴリズムを選んだのか」など、処理の意図や前提条件などをコメントとして書いておくと、あとからコードを読んだ人(あるいは自分自身)が理解しやすくなります。
ただし、コード自体がわかりやすく書かれていれば、コメントは最低限で済ませるほうがよい場合もあります。ドキュメント化の範囲や粒度は、チームの規模やプロジェクトの特性に合わせるのが基本です。
リファクタリング
リファクタリング とは、動作するコードの構造を整理・改善して可読性や保守性を高める作業です。
動作要件を変えずに、不要な重複コードをまとめたり、複雑な関数を分割したりする作業が該当します。大規模プロジェクトでは、リファクタリングを定期的に行なうことで、開発が進むにつれて肥大化しがちなコードを健全に保ちます。
Lesson 5Chapter 5.4バージョン管理の概要
バージョン管理 とは、ソースコードや資料などのファイルが「いつ・誰によって・どのように」変更されたのかを自動で記録・追跡できる仕組みです。
ソフトウェア開発では、バージョン管理が不可欠です。特に複数の人が同じコードを同時に編集する場合、誰がどの部分を変更したのかがわからないと、作業が衝突したり、原因不明のバグが生まれてしまうことがあります。バージョン管理を使うことで、こうした混乱を防ぎ、変更履歴をいつでも振り返ることができるようになります。
Git
Git は、世界で最も広く使われているバージョン管理システムの1つです。Gitの特徴は「分散型」という点で、以下のような仕組みで作業を進めることができます。
- ローカルリポジトリ
手元のパソコンにある作業用の領域(リポジトリ)で、ここにファイルの変更履歴が保管されます。 - リモートリポジトリ
インターネット上や社内サーバーなど、共有する場所に置いたリポジトリのことです。一般的に、GitHubやGitLabなどのサービスを使って管理します。 - ブランチ
コードの変更や新機能の開発を「枝わかれ」させて進めるための仕組みです。作業中のブランチが完成したら、他のブランチと合流(マージ)させることができます。 - マージ(統合)
ブランチでの変更内容を別のブランチに取り込む作業のことです。複数の開発者が同時に別の機能を開発していても、最終的に1つのブランチにまとめられます。 - コンフリクト(衝突)
同じファイルの同じ行を、複数のブランチが同時に違う内容で修正したときに起こる問題です。Gitでは、コンフリクトが発生すると自動的に知らせてくれるので、どのように解決するか(どちらを採用するかなど)を手動で判断できます。
チーム開発での活用イメージ
企業で行なうシステム開発や、オープンソースプロジェクトでは、GitHubやGitLabなどの「リモートリポジトリ」サービスがよく利用されます。各開発者は以下のように作業します。
- 自分のパソコン上(ローカルリポジトリ)で、作業用のブランチを作成します。
- 新機能の追加やバグ修正などを行ない、十分にテストします。
- 作業が完了したら、リモートリポジトリの「メインブランチ」(プロジェクトの中心となるブランチ)に、変更内容をマージします。
こうすることで、誰がどの部分をいつ変更したのかをかんたんに追跡でき、複数人が同時に開発していてもスムーズに統合できるメリットがあります。
Lesson 5Chapter 6プログラミングを体験してみよう
それでは、実際にプログラミングを体験してみましょう。
今回は paiza.io を利用します。
paiza.ioは、ブラウザ画面でプログラミングが行なえるサービスです。通常、プログラミングを行なう際は、パソコンにさまざまなツールをインストールして開発環境を構築する必要がありますが、paiza.ioは、すぐにコードを書いて実行できるので便利です。
paiza.ioのトップページ にアクセスし「コード作成を試してみる(無料)」のボタンをクリックしてください。なお会員登録すると、自分の作ったコードを一覧で確認できるので便利です。
エディター画面の左上で「Python3」を選択すると準備完了です。
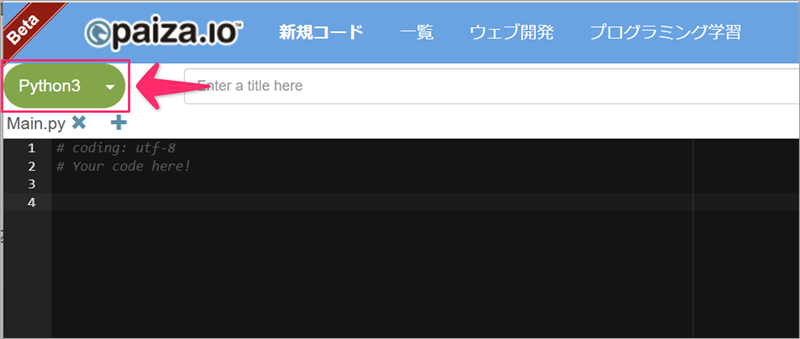
Lesson 5Chapter 6.1足し算
最初は、簡単な足し算を行なうプログラムを作成してみましょう。
フローチャート
2つの数値を足し合わせ、その結果を出力します。
ソースコード
Pythonのソースコードは以下のようになります。
x = 1 y = 2 result = x + y print(result)
それぞれの行が、フローチャートと対応していることがわかります。
x = 1は、xに1を「代入」するという意味です。プログラムでは=は「等しい」ではなく「代入」の意味になります。- 変数名「
xやy、result」は、自由に決めることができます。 print()は、カッコの中に指定された値を出力する命令です。print(result)で「resultを表示する」という意味になります。
実行結果
3
Lesson 5Chapter 6.2偶数・奇数を判定する
次は、条件分岐を行なってみましょう。
フローチャート
入力された整数が「偶数か、奇数か」を判定します。
ソースコード
Pythonのソースコードは以下のようになります。
# 整数を入力 n = 9 # 剰余を計算して判定 if n % 2 == 0: print("偶数です") else: print("奇数です")
ひし形で示した条件分岐を if で実装し、条件が満たされる場合とそうでない場合で処理がわかれています。
- 条件分岐は
if 条件:で書きます。 - 条件に該当した場合の処理を、続けて字下げ(インデント)して書きます。
#以降はコメントです。
n に代入する値を、いろいろと変えて試してみましょう。
実行結果
奇数です
Lesson 5Chapter 6.3合計値を計算する
次は、条件分岐を行なってみましょう。
フローチャート
数値の配列を入力し、それらの合計値を求めます。
ソースコード
Pythonのソースコードは以下のようになります。
# 配列を用意 array = [1, 2, 3, 4, 5] # 初期値を設定 sum = 0 # 配列の要素を1つずつ取り出して加算 for num in array: sum += num # 合計値を出力 print("合計:", sum)
- 配列(リスト)は
[1, 2, 3, 4, 5]のように書きます。 - 繰り返しは
for 要素名 in 配列(リスト):で書きます。 - 繰り返しの中の処理を、続けて字下げ(インデント)して書きます。
実行結果
合計: 15
Lesson 5Chapter 6.4送料込価格を計算する
最後に、実用的な例にチャレンジしてみましょう。チャプター3で取り上げた「送料込価格を計算する」問題のフローチャートを実装します。
フローチャート
「送料込価格を計算する」問題のフローチャートを再掲します。
ソースコード
Pythonのソースコードは以下のようになります。
# 税抜価格を入力 price_ex_tax = 1800 # 税込価格を計算 price_incl_tax = price_ex_tax * 1.1 # 送料を計算 if price_incl_tax >= 2000: shipping_fee = 0 else: shipping_fee = 350 # 送料込価格を出力 total_price = price_incl_tax + shipping_fee print("送料込価格は", total_price, "円です")
- 条件分岐は
if 条件:で書きます。 - 条件に該当しない場合の処理は
else:で書きます。
実行結果
送料込価格は 2330.0 円です
Lesson 5Chapter 7システムとプログラムの関係
企業や組織で運用されている業務システムやWebサービスは、単体のプログラムがそのまま動いているわけではありません。複数のプログラムやミドルウェア、外部サービスなどが組み合わさって動作し、ユーザーが求める処理やデータ連携を実現しています。
たとえば、売上データを夜間にまとめて計算するバッチ処理や、リアルタイムにアクセスして情報を返すWebアプリケーションなど、多彩な処理形態が存在します。プログラミングを学んだうえで視野をシステム全体に広げると、個々のプログラムがどんな役割を担い、どうやって全体のサービスを支えているのかが見えやすくなります。
このチャプターでは、システムの構成要素や代表的な処理形態、プログラム開発におけるテストやデバッグの必要性、そして性能やコストといった評価指標を整理します。プログラムを単体で動かすだけではなく、ビジネスの現場で安定して稼働させるために、どのような観点が求められるかを確認しましょう。
Lesson 5Chapter 7.1システムの構成と処理形態
システム とは、複数のプログラムやデータベース、ネットワーク、ハードウェアなどの要素が結びついて、特定の目的を達成する仕組みです。
たとえば、ブラウザから商品を購入できるECサイトでは、ユーザーが入力した注文情報を受け取るWebアプリケーション、在庫データを扱うデータベース、決済を担う外部サービスなどが連携し、全体として「商品の注文から決済まで」を自動化します。
ここでは、さまざまな観点から、システムの構成と処理形態について確認しましょう。
集中処理と分散処理
- 集中処理
コンピュータ資源を1か所(1台の大型コンピュータなど)に集約し、そのコンピュータがすべての処理を担う方式です。昔ながらのホストコンピュータ(メインフレーム)を中心に業務を回す形態が典型例です。大規模なデータを安定的に処理する場合に強みがありますが、負荷が集中しやすい、障害発生時の影響が大きいといったデメリットもあります。 - 分散処理
複数のコンピュータをネットワークで結び、処理を分散させる方式です。クラスタや分散データベースを組み合わせることで、性能向上や耐障害性を高められます。近年のクラウドサービスやマイクロサービスは、この分散処理の考え方に基づいて構築されることが多いです。
ホストコンピュータとシンクライアント
- ホストコンピュータ
企業や官公庁で古くから利用されてきた大型コンピュータ(メインフレーム)のことを指す場合が多いです。集中処理型のシステムでは、ホストコンピュータが全処理を担当し、端末は入出力を行なうだけの仕組みとなっていました。 - シンクライアント
ユーザーの操作端末(クライアント)にほとんど処理機能を持たせず、サーバー側でアプリケーションの実行やデータ管理を集中して行なう方式です。個々の端末にアプリケーションをインストールしなくてもよい、セキュリティ管理が容易といったメリットがありますが、ネットワークが不安定な場合は作業が滞る可能性もあります。
バッチ処理とリアルタイム処理
システムのなかでは、複数のプログラムが役割分担して動いています。フロントエンド(画面表示やユーザー操作)を担当するプログラムと、バックエンド(データベースアクセスやビジネスロジック)を担当するプログラムに分かれる例も多いです。また、以下のように、処理するタイミングによって大きく2つに分類できます。
- バッチ処理
一定の時間ごとにまとめてデータを処理する方法です。夜間や休日など、システムの負荷が低い時間帯に膨大な集計やバックアップを行ないます。たとえば売上データの集計や、メール一斉送信などに利用されます。リアルタイム性よりも安定性や大量データの一括処理を重視する場合に向いています。 - リアルタイム処理
ユーザーが操作を行なった瞬間に、その場で処理を実行する形態です。オンライン予約システムや銀行の口座残高照会、ECサイトの注文などで利用されます。新しい要求が来るたびにプログラムが動くため、タイムリーな応答が求められる場面で不可欠です。
サーバー環境と仮想化技術
プログラムが実行されるサーバー環境にも多様な選択肢があります。オンプレミス(自社サーバー)やクラウド(AWS, Azure, GCPなど)での稼働、あるいはコンテナ技術(DockerやKubernetesなど)を使う場合もあり、それぞれの特性を踏まえた運用が求められます。近年はクラウドインフラを活用し、負荷の変動に合わせてサーバー台数を柔軟に増減させる仕組みを取り入れる企業も増えています。
- サーバーの仮想化
仮想化ソフトウェア(Hypervisor)を使い、1台の物理サーバー上で複数の仮想サーバーを稼働させる技術です。仮想マシンごとに異なるOSを動かせるなど柔軟性が高く、サーバーリソースの利用効率も向上します。トラブル発生時に仮想マシンごと切り離して再起動できるため、保守や運用面でもメリットがあります。
システムの冗長構成
システムが停止しないように冗長構成を取ることは重要です。ハードウェアやソフトウェアに障害が起きた場合でも、別の系統ですぐに処理を引き継ぐことでサービス継続を目指します。代表的な構成例は次のとおりです。
- シンプレックスシステム(単一構成)
サーバーやネットワーク機器が1台のみで構成されるシステムです。構成がシンプルでコストは抑えられますが、故障するとシステムが止まってしまうリスクがあります。 - デュプレックスシステム(二重化構成)
メイン系と予備系を用意し、メイン系に障害があったときに予備系へ切り替えられるようにする構成です。自動的に切り替える「ホットスタンバイ」方式と、手動で切り替える「コールドスタンバイ」方式があります。 - デュアルシステム(並列稼働構成)
2つの系統を同時に稼働させて、結果を照合しながら処理を行なう構成です。常に結果を突き合わせるため高い信頼性が得られますが、コストや運用の複雑さも増します。航空管制や金融系のミッションクリティカルなシステムで採用されることがあります。
データストレージ構成
システムを支えるうえで、データをどのように保管・保護するかも重要です。サーバー内のハードディスクやSSDを単体で運用するだけでなく、RAIDやNASを用いて冗長性や拡張性を高める方法があります。
RAID(Redundant Array of Independent Disks)
複数のディスクを組み合わせて、信頼性や性能を向上させる仕組みです。以下のようなレベルがよく使われます。
- RAID1(ミラーリング):同じデータを複数のディスクに書き込み、片方が故障してもデータを失わないようにする方式。
- RAID5/RAID6(パリティ分散):データとパリティ情報を複数ディスクに分散配置し、1台(または2台)の故障であれば復旧可能にする方式。
- RAID0(ストライピング):ディスクを分割してデータを並列に書き込み、性能を上げる方式。ただし故障耐性はないため、障害時のリスクが大きくなります。
ほかにもRAID2〜4などの方式がありますが、実際に使われることは少なく、実運用ではRAID1/5/6がよく利用されます。
NAS(Network Attached Storage)
ネットワーク上に直接接続されたストレージ機器のことです。ファイルサーバー的に複数のクライアントからアクセス可能で、容量や台数を柔軟に増やすことができます。クラウドストレージやオンプレミスのNASを活用することで、大量データの共有やバックアップを行ないやすくなります。
直列システムと並列システム
システムの動作形態として、処理を直列的に行なうか、並列的に行なうかという視点も重要です。
- 直列システム(シリアル処理)
処理を1つずつ順番に実行する形態です。単純化しやすく、順序を厳密に管理する必要があるバッチ処理などで利用されるケースがあります。ただし大量の同時アクセスには弱いため、負荷が高くなると応答速度が低下しやすくなります。 - 並列システム(パラレル処理)
複数の処理を同時に実行する形態です。CPUのマルチコア活用や、分散システムでの負荷分散を行なうことで、高いスループットを実現できます。ただし、スレッドの安全性やデータの整合性など、開発時の考慮点が増えます。
Lesson 5Chapter 7.2ライブラリ・フレームワーク・API
システム開発では、「ライブラリ」や「フレームワーク」を活用することで、大量のコードを自作せずに効率よく機能を組み上げられます。さらに「API」を利用することで、外部サービスや別のシステムと連携がしやすくなります。
ライブラリ
ライブラリ は、汎用的な機能やクラス、関数がまとまった部品集です。たとえば、Pythonの標準ライブラリには文字列操作や日付処理などが用意されており、すぐに呼び出して使えます。
フレームワーク
フレームワーク は、アプリケーション全体の構造や基本的な流れを提供し、その上に独自のロジックを組み込める仕組みです。Webアプリを構築するフレームワークとしては、Pythonなら Django や Flask、Javaなら Spring、JavaScriptなら Express や Next.js などが有名です。フレームワークを使うと、ログイン機能やデータベース接続、ページ遷移などの定型処理を簡単に追加できます。
API
API(Application Programming Interface)は、プログラム同士がデータや機能をやり取りするためのインターフェースです。
多くの場合は、RESTやGraphQLなどの仕組みを用いて、HTTP経由でデータ交換を行ないます。たとえば天気情報APIからデータを取得すれば、自作アプリで天気予報を表示できます。また、地図や決済、音声認識など、専門性が高い機能を外部サービスからAPIとして呼び出すことで、開発コストを大幅に削減できます。
なぜライブラリやAPIを使うか
ライブラリやAPIの使用には、以下のようなメリットがあります。
- 開発効率:基本的な機能をゼロから実装する必要がなくなるため、開発期間を短縮できます。
- 品質の向上:信頼性の高いライブラリやフレームワークを使うことで、バグやセキュリティリスクを減らせます。
- 保守性の向上:コミュニティが活発なライブラリやAPIは、アップデートやセキュリティ修正が継続的に行なわれます。
Lesson 5Chapter 7.3プログラムのテストとデバッグ
システムの信頼性や品質を確保するには、「テスト」と「デバッグ」が欠かせません。個々のプログラムが単体で正しく動くかどうかだけでなく、システム全体の連携や運用時の負荷、エラー発生時のリカバリなど、多角的に確認する必要があります。
テストの種類
テストは、規模ごとに大きく3つの種類に分けられます。
- 単体テスト:個々の関数やクラス、モジュールが仕様通りに動くかを検証します。プログラム内部のロジックを細かくチェックするために必要です。
- 結合テスト:複数のモジュールや外部サービスが連携したときに、データの受け渡しや処理の流れが正しく行なわれるかを確認します。
- システムテスト:実際の運用環境に近い形で、ユーザーが想定する操作を行ない、不具合やパフォーマンス問題がないかを調べます。

デバッグ手法
バグが見つかったら、その原因を突き止めて修正します。ログを出力したり、デバッガツールを使って変数の状態を追いかけたりするのが一般的です。テスト環境をローカルやステージングサーバー上で用意し、デバッグが完了してから本番環境に反映するフローを組むことで、ユーザーへの影響を最小限に抑えられます。
品質を継続的に高める考え方
コードレビューや自動テスト(CI/CD)などを導入すれば、開発者が修正や新機能を追加するたびに自動でテストを回せます。問題があれば早期に気づけるため、不具合の混入リスクを下げられます。大規模な企業システムでは、テスターや品質管理部門がシナリオテストやリグレッションテストを実施し、リリース直前まで念入りに検証する体制を整えていることが多いです。

Lesson 5Chapter 7.4システムの評価指標
システムを本番運用する際には、性能面だけでなく信頼性や可用性、さらにコストなど、多角的な評価が求められます。
プログラム単体では問題なく動作していても、システム全体の観点で見ると改修が必要になる場合もあるため、総合的な視点での検証が不可欠です。
性能(スピード)
一度に多数のユーザーがアクセスしてきてもレスポンスが遅くならないようにする必要があります。Webアプリケーションでは、1秒未満の応答を目指すケースが多いでしょう。処理速度に影響する要因として、プログラムのアルゴリズムやデータベースのインデックス設計、サーバーのスペックなどが挙げられます。性能を最適化することは、ユーザー体験の向上だけでなく、システム全体の効率にも関わってきます。
信頼性(エラーの少なさ・MTBF・MTTR)
システムが停止したり不正なデータを出力したりすると、ビジネスに大きな影響を及ぼします。障害発生時にどう対処するか、復旧時間をいかに短縮するかといった運用面の設計が重要です。
障害から障害までの平均稼働時間(MTBF)が長いほど故障が少なく、平均修復時間(MTTR)が短いほど復旧が早いと判断できます。
クラスタリングや冗長構成(同じ処理ができるサーバーを複数台用意する)といった対策を取ることで、これらの指標をより良くすることが期待されます。
MTBF(平均故障間隔)
MTBF は「故障と故障の間(正常稼働している時間)の平均」を表す指標です。値が大きいほど故障までの時間が長い、つまり故障が起きにくい(信頼性が高い)システムといえます。計算式は以下のとおりです。
たとえば、あるシステムを 1,000 時間運用している間に、合計 5 回の故障が発生したとします。このときの MTBF は200時間となります。つまり「およそ 200 時間に 1 回」の頻度で故障が起きていることになります。
MTTR(平均修復時間)
MTTR は、システムが故障したときに、それを修復して再び稼働状態に戻すまでにかかる時間の平均を表します。値が小さいほど復旧が早い、つまり保守・運用体制が優れているシステムといえます。計算式は以下のとおりです。
上記と同じシステムで、5 回の故障の修復時間がそれぞれ 1 時間、2 時間、1 時間、3 時間、2 時間だったとします。合計修復時間は 1 + 2 + 1 + 3 + 2 = 9 時間です。つまり、このシステムが故障した場合は平均して約 1.8 時間 で復旧していることになります。
可用性(稼働率)
稼働率 は、システムが「利用可能な状態にある割合」を示す指標です。MTBF と MTTR から計算できるため、システムの「停止しにくさ(故障の少なさ)」と「復旧の早さ」の両方をまとめた評価指標といえます。稼働率が高いほどシステムは止まりにくく、止まっても素早く復旧できることを意味します。計算式は以下のとおりです。
先ほどの例で「MTBF = 200 時間、MTTR = 1.8 時間」と求めました。このときの稼働率は、約98.23%となります。つまり、100 時間の稼働のうち約 98.23 時間はシステムが動いている(利用可能な)状態です。
経済性(コスト)
開発コストだけでなく、サーバー利用料や保守・運用にかかる人件費などを総合的に考える必要があります。
- 高性能なサーバーを用意すればスピードが向上し、結果として稼働率も上がるが、その分コストも膨れ上がる可能性があります。
- クラウド環境ではスケールアップやスケールダウンが容易な反面、継続的な利用料がかかることに留意しなければなりません。
稼働率や信頼性を高めるほどコストは増大しがちなので、システムの重要度や予算に応じて最適なバランスを検討することが大切です。
Lesson 5Chapter 8まとめ
このレッスンでは、ビジネスや日常業務のさまざまなシーンでアプリケーションが活用されており、その基礎となるのが「アルゴリズム」と「プログラミング」であることを学びました。複雑な問題を細かく分解し、最適な手順(アルゴリズム)を設計し、その手順をコンピューターが理解できる形(プログラミング)で実装する流れが、効率的な業務オペレーションや新しいサービス創出の土台になります。
単純な計算処理やデータ抽出に限らず、大量データの分析や高度な自動化を行なうときにも、アルゴリズムとプログラミングが重要な役割を果たします。ビジネスパーソンがこうした基礎を理解しておくと、エンジニアに的確な依頼を出せるだけでなく、自分たちの業務に合った改善策を主体的に考え、実装や導入をリードできるようになります。
このレッスンで学んだこと
このレッスンで学んだことを振り返り、理解度を確認しましょう。
- プログラミング思考は、プログラムを書く前に行なう「問題解決のための考え方」のこと。大きな課題を小さなサブタスクに分解し、ゴールや入力・出力を明確にして手順を組み立てる。
- アルゴリズムは、入力データを所定のルールで処理し、望む結果を得るための「問題解決の手順」。制御構文(逐次処理、条件分岐、繰り返し)や変数の使い方を意識して、コンピューターが理解できる形に整理する。
- フローチャートは、処理や分岐を「記号」と「矢印」で可視化した図。処理の抜け漏れを防ぎ、関係者間の認識を揃えるうえで有用。
- 合計値や平均値、最大値・最小値など基本的な計算アルゴリズムを学び、探索(線形探索・二分探索)やソート(バブルソート)で処理効率の違いを知る。
- プログラミング言語は、コンパイル型(C/C++、Javaなど)とインタプリタ型(Python、Ruby、JavaScriptなど)の2種類があり、それぞれ実行速度や移植性で特徴が異なる。
- コードの保守性を高めるには、可読性を意識したコーディング規約の導入やコメントの活用が重要。変更履歴を追跡できるGitなどのバージョン管理ツールも必須。
- システムは単体のプログラムのみでなく、複数のプログラム・ミドルウェア・外部サービスなどが連携して動作する。バッチ処理やリアルタイム処理、冗長構成など、運用形態は多岐にわたる。
- テストには、単体テスト・結合テスト・システムテストがあり、デバッグと併せてバグを早期発見・修正する工程が重要。継続的に品質を高めるため、CI/CDやコードレビューを導入する場合もある。
- システムの評価指標として、処理速度やメモリ使用量だけでなく、可用性(MTBF、MTTR、稼働率)やコストなど総合的な視点が求められる。
- アルゴリズムやプログラミングの基礎を理解することで、エンジニアとの連携が円滑になり、自分たちの業務に合わせたアプリケーション作成や業務改善のリードが可能になる。
課題アルゴリズムとプログラミングの理解度確認
下記の5つの質問に答えてください。「回答フォーマット」をコピーして、コメント欄に記入して提出してください。
- プログラミング思考とは何でしょうか?
- アルゴリズムの重要な要素について説明してください。
- インタプリタ型言語の特徴を簡潔に説明してください。
- テスト工程の「結合テスト」とはどのようなものですか?
- アプリケーションを作成する際、アルゴリズムとプログラミングを理解する利点は何ですか?
回答フォーマット
1.
2.
3.
4.
5.